
【论文标题】 Read, Listen, and See: Leveraging Multimodal Information Helps Chinese Spell Checking
【作者团队】Heng-Da Xu,Zhongli Li,Qingyu Zhou,Chao Li,Zizhen Wang,Yunbo Cao,Heyan Huang,Xian-Ling Mao
【机构】北京理工大学,腾讯
【论文链接】https://arxiv.org/pdf/2105.12306.pdf
【推荐理由】
本文来自北理工和腾讯,收录于ACL Findings 2021。文章提出了一种新的多模态模型用于中文拼写检查。
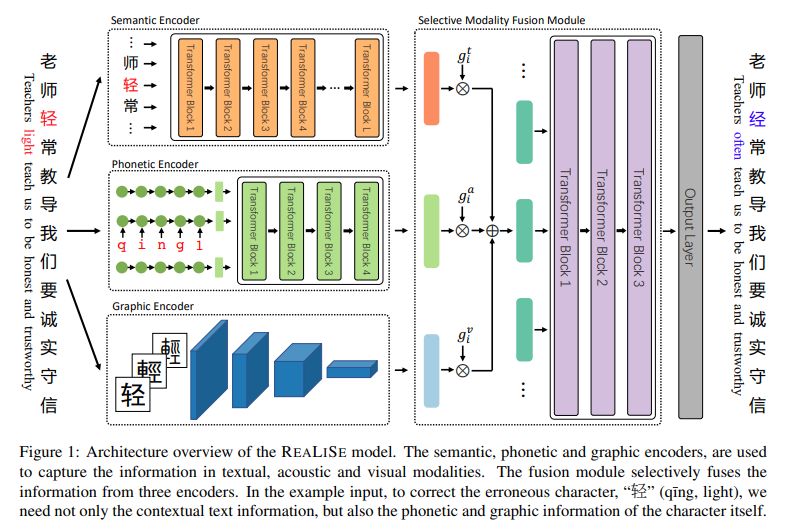
中文拼写检查(CSC)的目的是检测和纠正用户生成的中文文本中的错误字符。大多数的中文拼写错误都是在语义、语音或图形上被误用的相似字符。以前的工作注意到了这一现象,并尝试将相似性用于此任务。但是,这些方法使用启发式或手工制作的混淆集来预测正确的字符。本文提出了一种直接利用汉字多模态信息的汉字拼写检查器REALISE模型。该模型处理CSC任务的方法是:(1)捕获输入字符的语义、语音和图形信息;(2)有选择地混合这些模式中的信息以预测正确的输出。在SIGHAN基准上的实验表明,该模型的性能明显优于强基线。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢