
近来,围绕着 "少样本命名实体识别"(few-shot NER)这一主题,出现了大量的工作和文献。“少样本命名实体识别”任务具有实际应用价值,也充满挑战性。
但是目前鲜有专门针对该任务的基准数据,之前的大多数研究都是通过重新组织现有的有监督NER数据集,使其成为“少样本”场景下的数据集。这些策略通常旨在通过少量的例子来识别粗粒度的实体类型,而在实践中,大多数实体类型都是细粒度的。
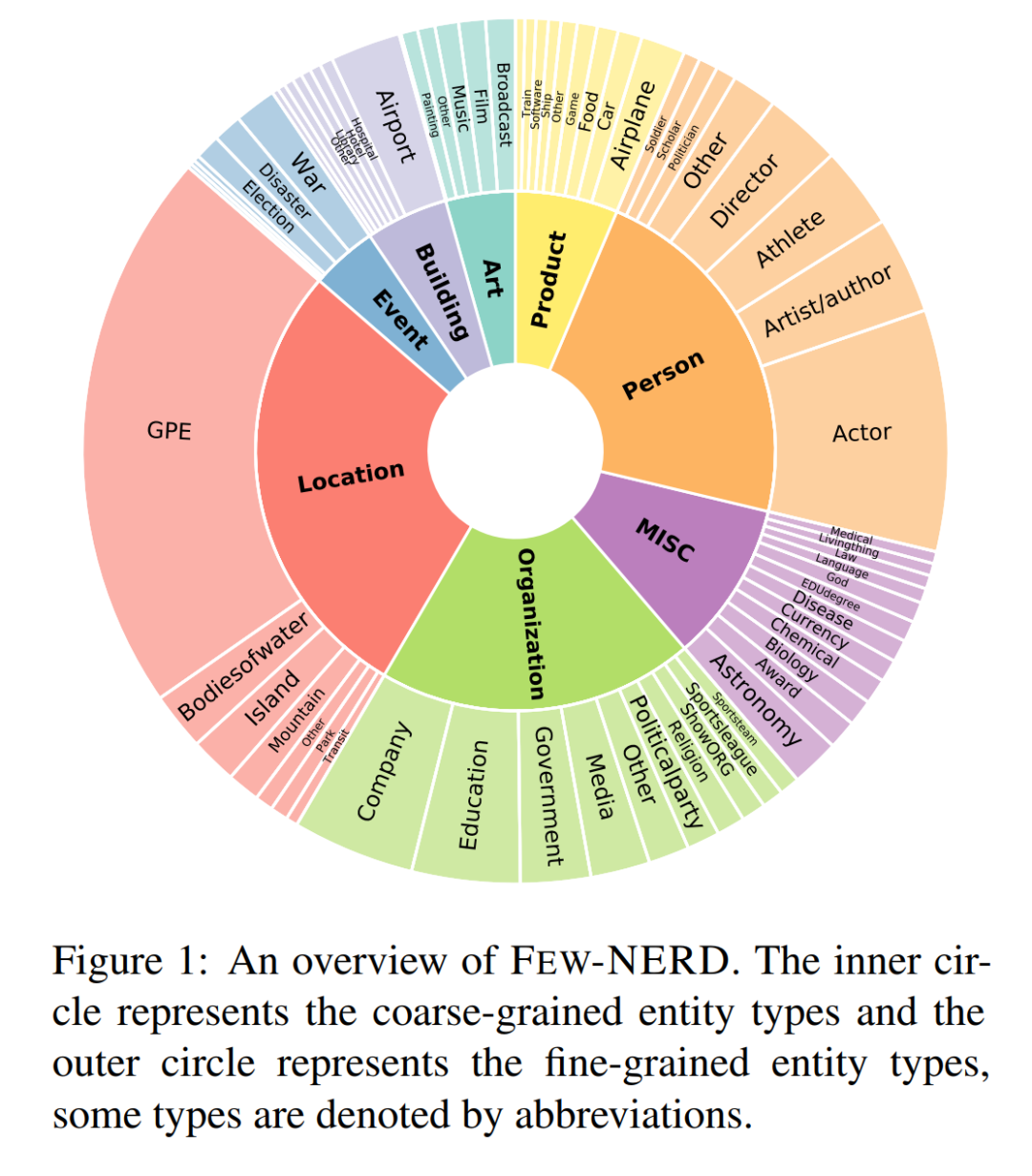
在本文中,清华大学联合阿里巴巴发布了Few-NERD,一个大规模的人工标注的用于few-shot NER任务的数据集。
该数据集包含8种粗粒度和66种细粒度实体类型,每个实体标签均为粗粒度+细粒度的层级结构,共有188,238个来自维基百科的句子,4,601,160个词,每个词都被注释为上下文(context)或一个实体类型的一部分。这是第一个few-shot NER数据集,也是最大的人工标注NER数据集。
研究人员构建了具有不同侧重点的基准任务来全面评估模型的泛化能力。广泛的实证结果和分析表明,few-shot NER任务充满挑战性,亟待进一步研究。
- 论文链接:https://arxiv.org/abs/2105.07464
- 网站链接:http://ningding97.github.io/fewnerd/
- 开源链接:https://github.com/thunlp/Few-NERD
感兴趣的可以继续戳原文。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢