
论文标题:An Attention Free Transformer
论文链接:https://arxiv.org/abs/2105.14103
作者单位:Apple
即插即用!无需任何架构改变,皆可集成到现有的Transformer中,直接替换MHA(或诸如dot product attention)!使得网络更加高效,在NLP和CV中均适用!还提出了AFT-local 和 AFT-conv两种变体。
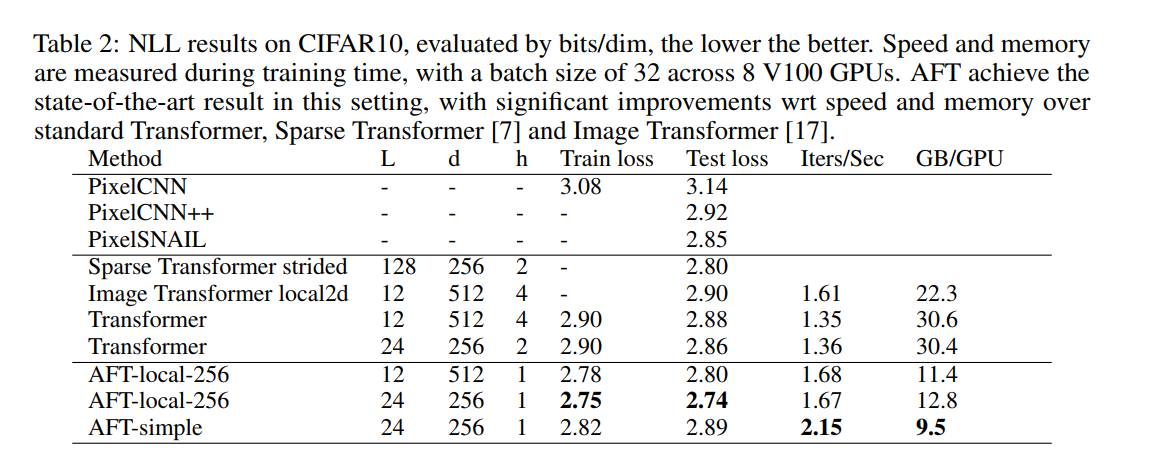
我们提出了Attention Free Transformer (AFT),这是一种高效的 Transformer 变体,它消除了对dot product self attention的需要。在 AFT 层中,key和 value首先与一组学习的位置偏差相结合,其结果以element-wise与查询相乘。 这个新操作的内存复杂度为线性 w.r.t. 上下文大小和特征维度,使其兼容大输入和模型大小。 我们还介绍了 AFT-local 和 AFT-conv,这两种模型变体在保持全局连接的同时利用了局部性和空间权重共享的思想。 我们对两个自回归建模任务(CIFAR10 和 Enwik8)以及一个图像识别任务(ImageNet-1K 分类)进行了大量实验。 我们展示了 AFT 在所有基准测试中都表现出具有竞争力的性能,同时提供了出色的效率。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢