
【论文标题】MVIT: MASK VISION TRANSFORMER FOR FACIAL EXPRESSION RECOGNITION IN THE WILD
【作者团队】Hanting Li, Mingzhe Sui, Feng Zhao, Zhengjun Zha, and Feng Wu
【机构】中国科学技术大学
【发表时间】2021/6/9
【论文链接】https://arxiv.org/pdf/2106.04520.pdf
【推荐理由】
本文为了解决开放环境下人脸识别任务中,由于图像背景的复杂性等问题导致模型在有限规模的数据集上学习鲁棒性不足的问题,提出了MVIT:用于野外人脸表情识别的掩模视觉Transformer。
MViT由两个模块组成:基于变换器的面具生成网络(MGN),生成一个能够滤除复杂背景和人脸图像遮挡的面具,以及一个动态重新标记模块,用于纠正野外FER数据集中的错误标记。模型的结构示意图如图1所示,模型在 ImageNet 上预训练的 DeiT-S作为分类器,人脸图像被馈送到 MGN 以生成相应的掩码,该掩码可以衡量不同区域的重要性并过滤掉复杂的背景和遮挡,然后利用 MViT 来确定掩码图像的表达。同时,在训练过程中,作者设计了一个动态重新标记模块来纠正可疑的错误标签。
在实验部分,作者经过大量实验测试,结果表明,MViT在RAF-DB上的性能优于现有的方法。
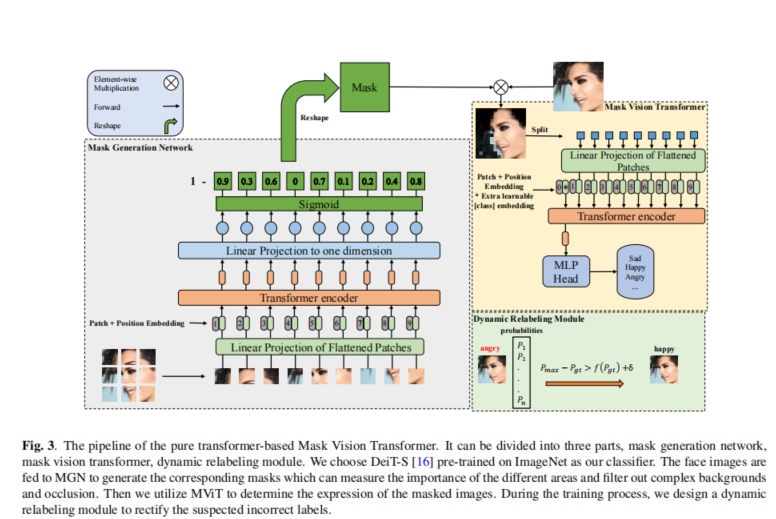
图1:MVIT结构示意图
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢