
论文标题:Video Instance Segmentation using Inter-Frame Communication Transformers
论文链接:https://arxiv.org/abs/2106.03299
作者单位:延世大学 & Adobe研究院
表现SOTA!性能优于MaskProp、VisTR (CVPR 2021)等网络,速度高达107 FPS!代码即将开源!
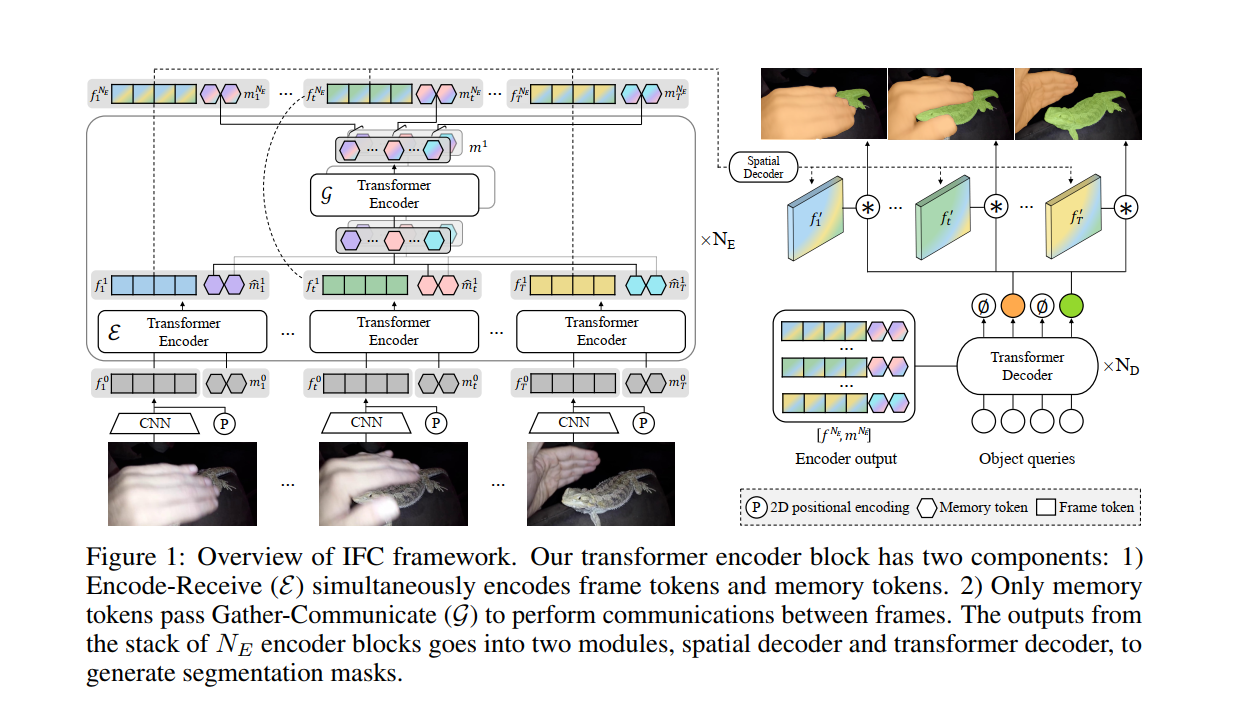
我们提出了一种基于Transformer的新型视频实例分割(VIS)端到端解决方案。最近,与利用来自多个帧的更丰富信息的每帧方法相比, per-clip pipeline显示出优越的性能。然而,以前的 per-clip 模型需要大量的计算和内存使用来实现帧到帧的通信,限制了实用性。在这项工作中,我们提出了帧间通信Transformer (IFC),它通过有效地编码输入剪辑中的上下文,显著减少了帧之间信息传递的开销。具体来说,我们提出使用简洁的记忆token作为传达信息以及总结每个帧场景的手段。通过精确编码的记忆token之间的信息交换,每个帧的特征都得到丰富并与其他帧相关联。我们在最新的基准测试集上验证了我们的方法,并获得了最先进的性能(YouTube-VIS 2019 验证集上的 AP 44.6 使用离线推理),同时具有相当快的运行时间(89.4 FPS)。我们的方法也可以应用于近乎在线的推理,以实时处理视频,只有很小的延迟。该代码将可用。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢