标题:清华、智源、循环AI|FASTMOE: A FAST MIXTURE-OF-EXPERT TRAINING SYSTEM(FASTMOE:快速混合专家训练系统)
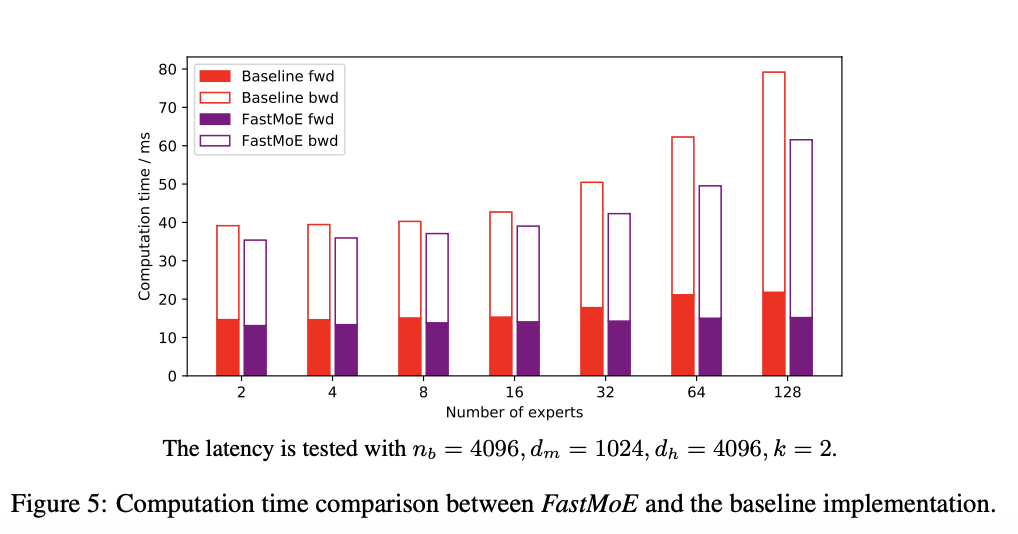
简介:专家混合(MoE)在将语言模型的规模扩大到数万亿个参数方面具有强大的潜力。然而,训练万亿规模的 MoE 需要算法和系统协同设计,以实现良好调优的高性能分布式训练系统。不幸的是,唯一满足要求在很大程度上取决于 Google 的硬件 (TPU) 和软件 (Mesh-Tensorflow) 堆栈,并且不对公众开放,尤其是 GPU 和PyTorch 社区。在本文中,我们提出了 FastMoE,一种基于分布式 MoE 训练系统带有常见加速器的 PyTorch。系统提供分层界面灵活的模型设计和轻松适应不同的应用程序,例如Transformer-XL 和 Megatron-LM。与直接执行不同MoE 模型使用 PyTorch,训练速度在 FastMoE 中被高度优化复杂的高性能加速技能。系统支持放置跨多个节点的多个 GPU 上的不同专家,从而能够扩大专家数量与 GPU 数量呈线性关系。
代码下载:https://github.com/laekov/fastmoe
论文下载:https://arxiv.org/pdf/2103.13262v1.pdf
内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢