
【论文标题】Fair Classification with Adversarial Perturbations
【作者团队】L. Elisa Celis, Anay Mehrotra, Nisheeth K. Vishnoi
【发表时间】2021/06/10
【机 构】耶鲁大学
【论文链接】https://arxiv.org/pdf/2106.05964.pdf
【代码链接】https://github.com/AnayMehrotra/Fair-classification-with-adversarial-perturbations
【推荐理由】本文出自耶鲁大学,针对在对抗性环境中,先前的方法对错误做出随机或独立假设的程度可能满足他们的准确性问题,本文提出了一个优化框架,用于在这种对抗性环境中学习公平分类器,并提供可证明的准确性和公平性保证。
本文在一个无所不知的对手存在的情况下研究公平分类,给定一个η,允许选择任意η-部分训练样本并任意扰乱其受保护的属性。动机来自受保护属性可能由于战略误报、恶意行为者或插补错误而引起的错误设置;在这种对抗性环境中,先前的方法对错误做出随机或独立假设的程度可能无法满足他们的准确性。本文的主要贡献是一个优化框架,用于在这种对抗性环境中学习公平分类器,并提供可证明的准确性和公平性保证。框架适用于多个和非二进制受保护属性,专为大类线性分数公平性度量而设计,并且还可以处理除受保护属性之外的扰动。实验证明了本文的框架对自然假设类的保证近乎严格:没有算法可以有明显更好的准确性,任何具有更好公平性的算法都必须具有较低的准确性。根据经验,本文还评估了框架生成的分类器,并用于对一系列对手的真实世界和合成数据集的统计率。
下图为使用本文提出的优化框架,对数据进行模拟的评估结果。总体显示优于其它模型。
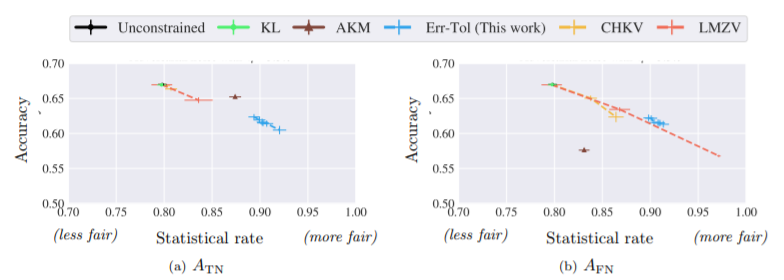
图1 COMPAS数据模拟结果评估
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢