
【论文标题】BEIT: BERT Pre-Training of Image Transformers
【作者团队】Hangbo Bao , Li Dong, Furu Wei
【机构】微软
【发表时间】2021/6/16
【论文链接】https://arxiv.org/pdf/2106.08254.pdf
【推荐理由】
本文为了解决目前Transformer在图像处理任务中,将类似于bert的预训练用于图像处理任务中比较困难的问题,提出了BERT 图像Transformer预训练(BEIT)。
BEIT是一种基于图像Transformer双向编码器表示的自监督的视觉表示模型。作者提出了蒙版图像建模(MIM)方法,将每个图像分为图像块和视觉标记(即离散标记)两个部分,再将图像分割成一个补丁网格作为主干 Transformer 的输入,此外,作者将通过离散 VAE 的潜在代码获得的图像“标记化”为离散视觉标记。 在预训练期间,随机屏蔽部分图像块,并将损坏的输入提供给 Transformer学习恢复原始图像的视觉标记,而不是蒙版补丁的原始像素。预训练结束后,作者通过在预训练的编码器上附加任务层来直接微调下游任务的模型参数。BEIT结构示意图如图1所示。
在实验部分,作者在图像分类和语义分割任务上分别进行了实验,结果表明,BEIT取得了最新的成绩。
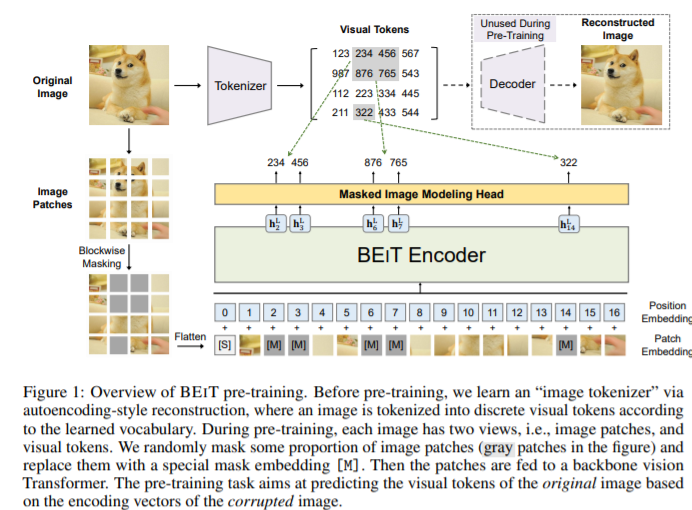
图1: BEIT结构示意图
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢