标题:快手|MlTr: Multi-label Classification with Transformer(MlTr:使用变换器进行多标签分类)
https://github.com/starmemda/MlTr/
https://arxiv.org/pdf/2106.06195v1.pdf
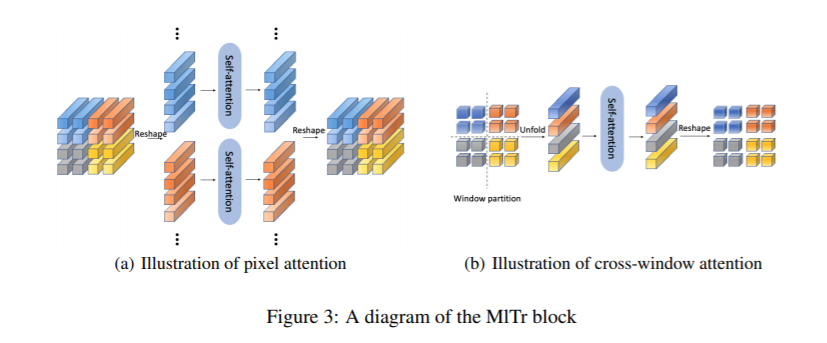
内容中包含的图片若涉及版权问题,请及时与我们联系删除

https://github.com/starmemda/MlTr/
https://arxiv.org/pdf/2106.06195v1.pdf
内容中包含的图片若涉及版权问题,请及时与我们联系删除
沙发等你来抢

评论
沙发等你来抢