
论文标题:LegoFormer: Transformers for Block-by-Block Multi-view 3D Reconstruction
论文链接:https://arxiv.org/abs/2106.12102
代码链接:https://github.com/faridyagubbayli/LegoFormer
作者单位:慕尼黑工业大学 & 谷歌
表现SOTA!性能优于Pix2Vox++、3D-R2N2等网络,还演示了如何使用自注意力来提高模型输出的可解释性,代码即将开源!
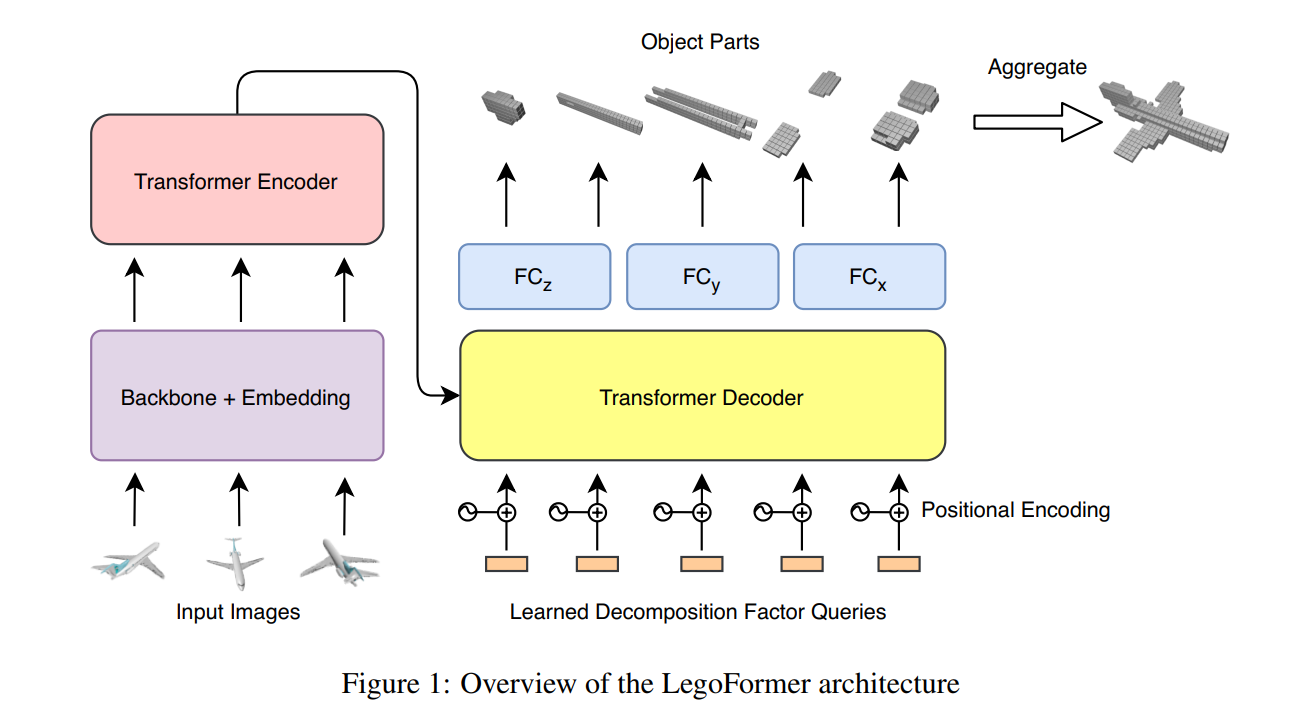
大多数现代基于深度学习的多视图 3D 重建技术使用 RNN 或融合模块在编码后组合来自多个图像的信息。 这两个单独的步骤具有松散的联系,并且在对每个视图进行编码时不考虑所有可用信息。 我们提出了 LegoFormer,这是一种基于Transformer的模型,它在单个框架下统一物体重建,并通过其分解因子参数化重建的占用网格。 这种重构允许将对象预测为一组独立的结构,然后聚合以获得最终的重建。 在 ShapeNet 上进行的实验显示了我们网络相对于最先进方法的竞争性能。 我们还演示了如何使用自注意力来提高模型输出的可解释性。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢