

论文标题:Transformer Meets Convolution: A Bilateral Awareness Net-work for Semantic Segmentation of Very Fine Resolution Ur-ban Scene Images
论文链接:https://arxiv.org/abs/2106.12413
作者单位:武汉大学
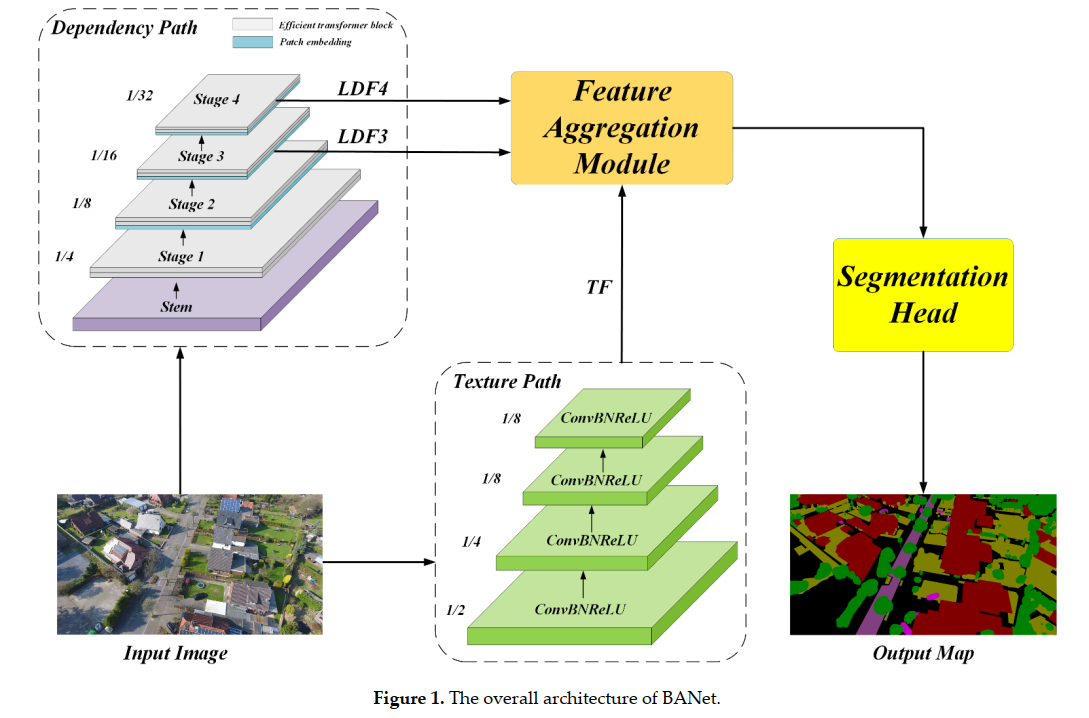
本文提出了一个双边感知网络(BANet),包含一个依赖路径和一个纹理路径,其中使用了ResT:一种具有内存高效多头自注意力的新型 Transformer主干,优于ShelfNet、SwiftNet等网络。
超高分辨率 (VFR) 城市场景图像的语义分割在自动驾驶、土地覆盖分类和城市规划等多个应用场景中发挥着重要作用。 然而,VFR 图像中包含的大量细节严重限制了其潜力。现有的深度学习方法。更严重的是,对象的尺度和外观的显著变化进一步降低了这些语义分割方法的表示能力,导致相邻对象的混淆。解决这些问题代表了遥感界一个有前途的研究领域,为场景级景观格局分析和决策铺平了道路。在这个文章中,我们提出了一个双边感知网络(BANet),它包含一个依赖路径和一个纹理路径,以完全捕捉 VFR 图像中的远程关系和细粒度细节。具体来说,依赖路径是基于 ResT 进行的,ResT 是一种具有内存高效多头自注意力的新型 Transformer 主干,而纹理路径建立在堆叠卷积操作上。此外,使用线性注意力机制,设计了一个特征聚合模块(FAM)来有效地融合依赖特征和纹理特征。在三个大型城市场景图像分割数据集(即 ISPRS Vaihingen 数据集、ISPRS Potsdam 数据集和 UAVid 数据集)上进行的大量实验证明了我们 BANet 的有效性。具体来说,在 UAVid 数据集上实现了 64.6% mIoU。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢