【论文标题】Video Swin Transformer
【作者团队】Ze Liu,Jia Ning,Yue Cao,Yixuan Wei,Zheng Zhang,Stephen Lin,Han Hu
【发表时间】2021/06/24
【机构】微软亚洲研究院、中国科学技术大学、华中科技大学、清华大学
【论文链接】https://arxiv.org/abs/2106.13230
【代码链接】https://github.com/SwinTransformer/Video-Swin-Transformer
本文出自微软亚洲研究院、中国科学技术大学、华中科技大学、清华大学,作者针对视频识别任务对图像域的 Swin Transformer 进行了修正,成功地向视频 Transformer 中引入了局部归纳偏置,效果 SOTA。
Transformer 正逐渐成为计算机视觉研究社区关注的重点。纯粹的 Transformer 架构已经在主要的视频识别对比基准上达到了最高的精确度。这些视频模型以 Transformer 为基础,它们能够在时空维度上全局地将图块联系起来。
在本文中,作者主张在视频 Transformer 中引入局部的归纳偏置。之前的视觉 Transformer 都是以全局自注意力为基础的,本文提出的方法可以更高地平衡运算速度和准确率。本文提出的视频架构的局部性是通过对针对图像域设计的 Swin Transformer 进行调整来实现的,同时利用了预训练图像模型的能力。本文提出的方法在多个视频识别对比基准上获得了最先进的准确率。
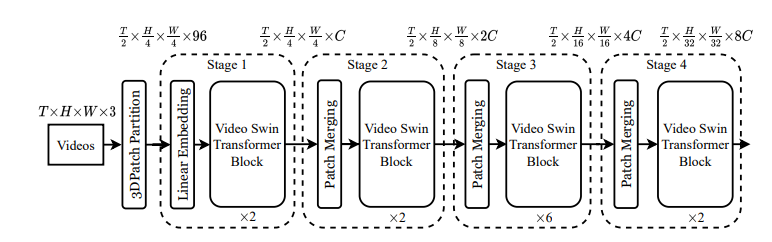
图 1:视频 Swin Transformer 架构示意图
内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢