标题:阿里|Exploring Sparse Expert Models and Beyond(探索稀疏专家模型)
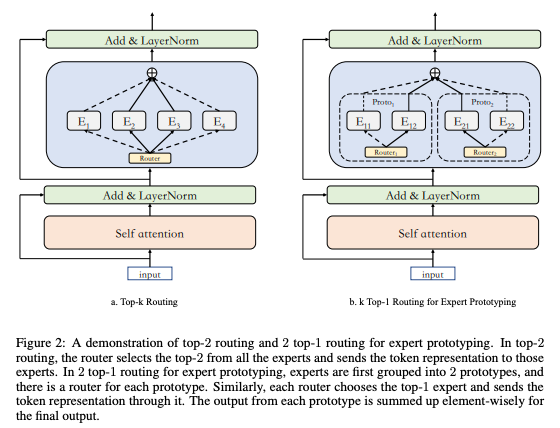
简介:专家混合模型可以以惊人参数量且恒定计算成本取得较好结果,因此成为模型缩放的趋势。 MoE 层如何通过利用稀疏激活的参数带来质量提升仍然是一个谜。我们观察到负载不平衡可能不是影响模型质量的重大问题,而top-k 路由中的稀疏激活专家的数量专家能力可以显着影响上下文。此外,我们提出了称为专家原型一种简单的方法,将专家分成不同的原型并应用k个top-1 路由。这种策略提高了模型质量但保持不变计算成本,以及我们对超大规模模型的进一步探索反映它在训练更大的模型时更有效。我们推模型扩展到超过 1 万亿个参数并仅在 480 个 NVIDIA V100-32GB GPU,与在 2048 个 TPU 内核上,所提出的巨型模型在收敛上实现了加速。
论文地址:https://arxiv.org/pdf/2105.15082.pdf
内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢