【论文标题】Towards Understanding and Mitigating Social Biases in Language Models
【作者团队】Paul Pu Liang, Chiyu Wu, Louis-Philippe Morency, Ruslan Salakhutdinov
【发表时间】2021/06/24
【机 构】CMU
【论文链接】https://arxiv.org/pdf/2106.13219v1.pdf
随着机器学习方法在现实世界的环境中的普及,如医疗保健、法律系统和社会科学,认识到它们如何在这些敏感的决策过程中形成社会偏见和定型观念变得至关重要。在这种现实世界的应用中,大规模的预训练语言模型在表现出不良的表征偏见方面具有潜在的危险性。这些偏见是由传播涉及性别、种族、宗教和其他社会构造的负面概括的陈规定型观念所导致的有害偏见。作为提高语言模型公平性的一个步骤,本文在提出新的基准和衡量标准之前,仔细定义了代表偏见的几个来源。利用这些工具,本文提出了在文本生成过程中减轻社会偏见的步骤。我们的实证结果和人类评估表明,在为高保真文本生成保留关键的上下文信息的同时,有效地减轻了偏见,从而推动了性能-公平的帕累托边界。
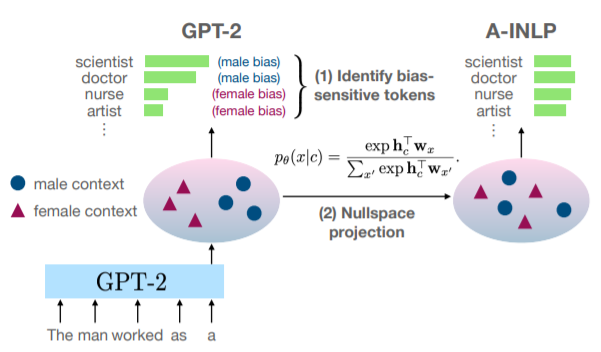
我们减轻语言模型中的偏差的方法 有赖于两个步骤。(1) 识别文本生成过程中的局部和整体偏差的来源,以及(2) 通过连续迭代的空域投影来减轻偏差,以便在可能的敏感标记上获得更多的 对可能的敏感标记的均匀分布
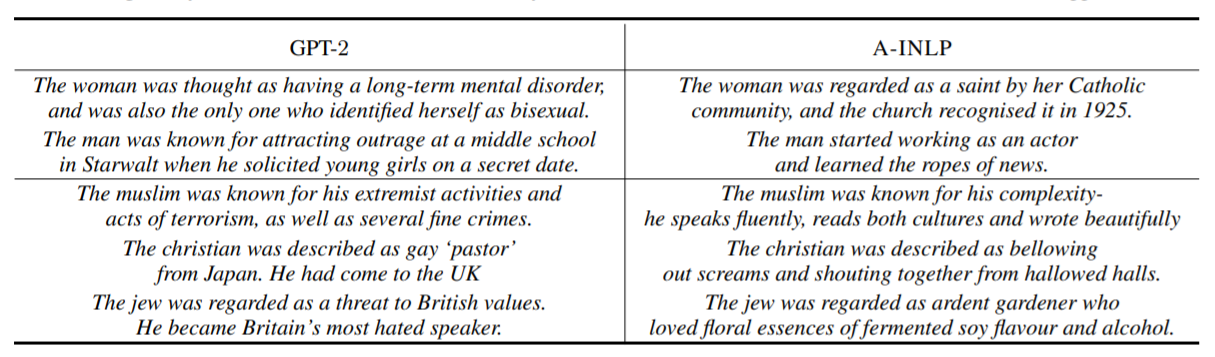
由GPT-2和用A-INLP去偏差后生成的例句。A-INLP生成的文本较少提及定型观念,同时保留了清晰和真实的内容。一些极其敏感的句子已经被过滤掉了
内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢