标题:波恩大学、Zerotha|VOGUE: Answer Verbalization through Multi-Task Learning(VOGUE:通过多任务学习回答语言化)
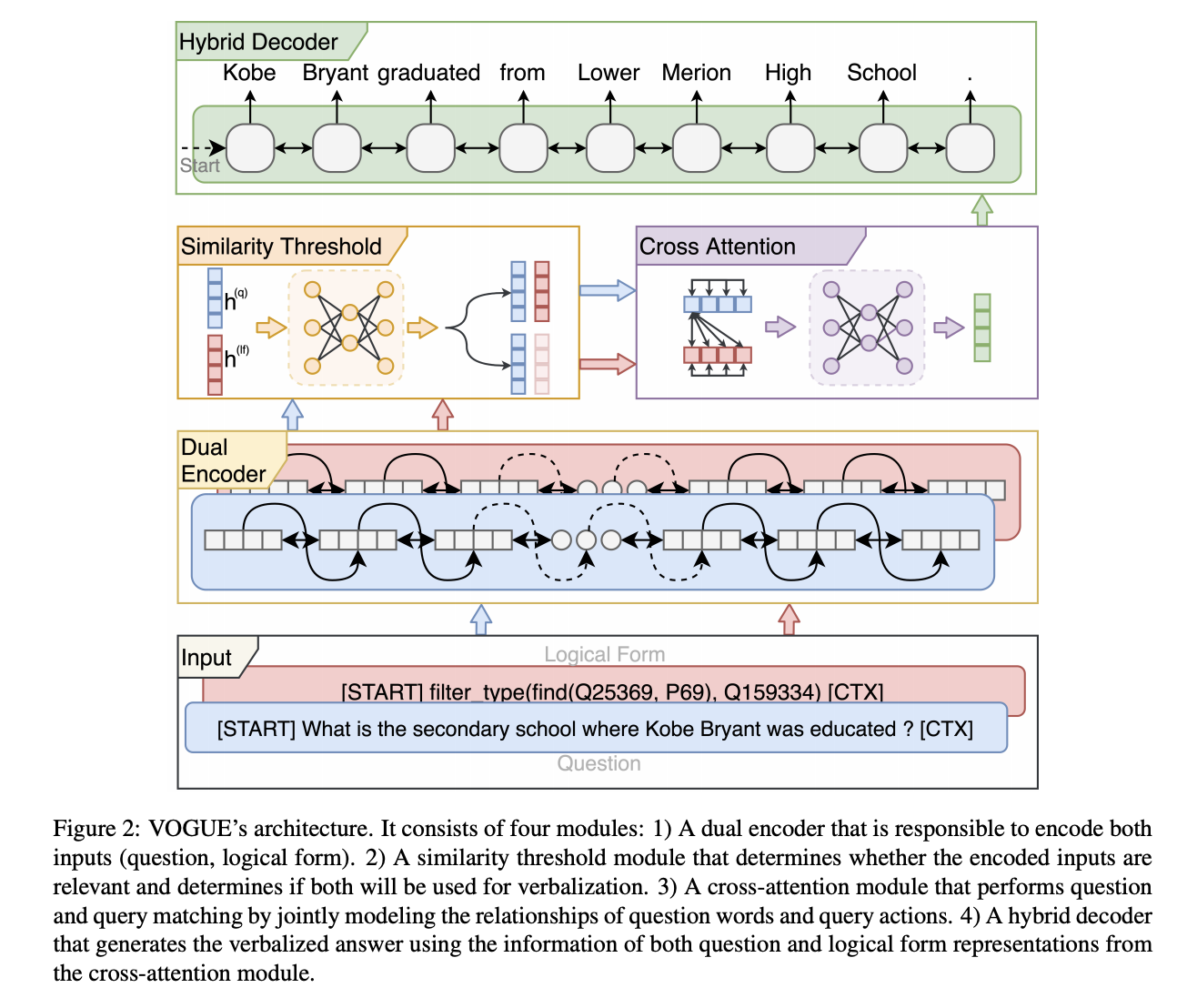
简介:近年来,知识图谱问答(KGQA)发生了显着的发展。尽管所有显着的进步,当前的知识图谱问答系统只关注答案生成技术而不是回答口头表达。然而,在真实场景中,用户更喜欢口头回答而不是生成的响应。本文解决了复杂问题的答案语言化任务知识图谱。在这种情况下,我们提出了一种基于多任务的回答措辞框架:VOGUE。VOGUE框架尝试通过多任务学习范式使用混合方法生成口头回答。我们的框架可以生成基于使用问题的结果和查询同时作为输入。VOGUE包含四个模块,通过多任务学习同时训练。我们在所有现有数据集上评估我们的框架用于回答语言表达,它的表现在BLEU和METEOR分数的作为评估指标优于所有当前基线。
代码下载:https://github.com/endrikacupaj/VOGUE
论文地址:https://arxiv.org/pdf/2106.13316v2.pdf
内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢