
论文标题:Post-Training Quantization for Vision Transformer
论文链接:https://arxiv.org/abs/2106.14156
作者单位:北京大学 & 华为诺亚方舟实验室 & 鹏城实验室
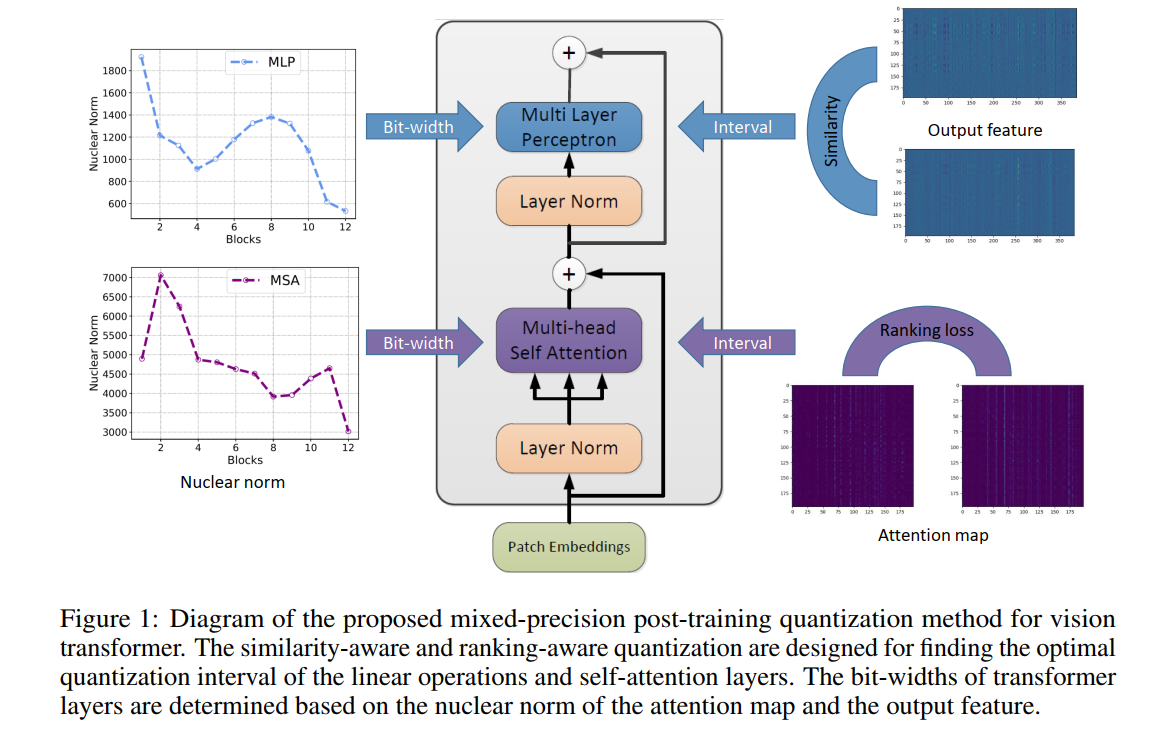
本文为视觉Transformer开发了一种新的训练后量化方案,其中每层的位宽基于transformer层中的注意力图和输出特征的核范数而变化,表现SOTA!优于Bit-Split、EasyQuant等方法。
最近,Transformer 在各种计算机视觉应用中取得了卓越的性能。与主流的卷积神经网络相比,视觉Transformer通常具有用于提取强大特征表示的复杂架构,在移动设备上更难开发。在本文中,我们提出了一种有效的训练后量化算法,用于减少视觉Transformer的内存存储和计算成本。基本上,量化任务可以被视为分别为权重和输入寻找最佳的低位量化间隔。为了保持注意力机制的功能,我们在传统的量化目标中引入了ranking损失,旨在保持量化后自注意力结果的相对顺序。此外,我们深入分析了不同层的量化损失与特征多样性之间的关系,并通过利用每个注意力图和输出特征的核范数探索混合精度量化方案。在多个基准模型和数据集上验证了所提出方法的有效性,其性能优于最先进的训练后量化算法。例如,我们可以在大约 8 位量化的 ImageNet 数据集上使用 DeiT-B 模型获得 81.29\% top-1 的准确率。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢