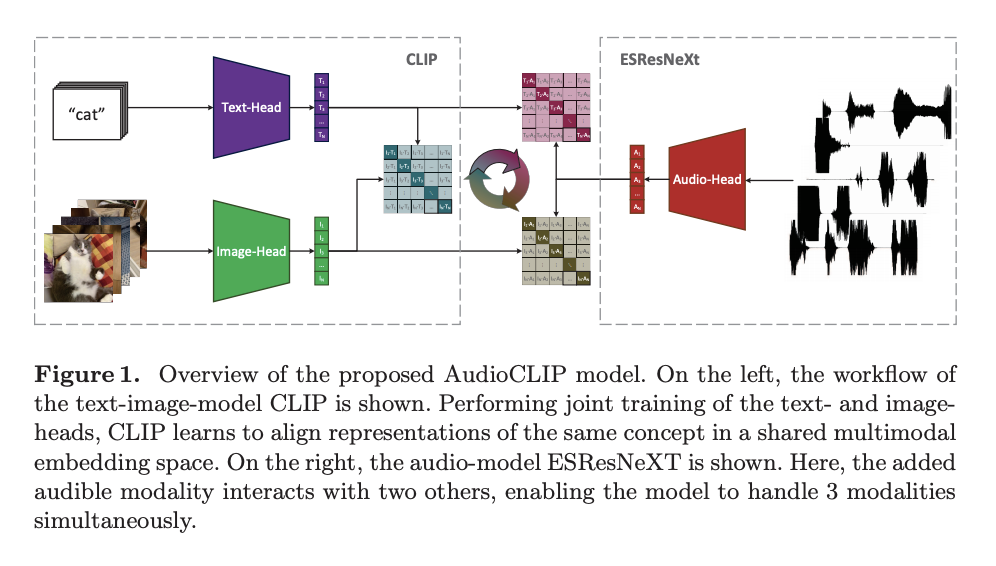
简介:过去,快速发展的声音分类领域大大受益于其他领域方法的应用。今天,我们观察到融合特定领域任务和方法共同为社区提供了新的优秀模型的趋势。在这项工作中,我们展示了 CLIP 模型的扩展,除了文本和图像之外,它还处理音频。我们提出的模型包含使用 AudioSet 将 ESResNeXt 音频模型转换为 CLIP 框架数据集。这种组合使所提出的模型能够执行双峰和单峰分类和查询,同时保持 CLIP 的以零样本推理方式泛化到未知数据集的能力。AudioCLIP 在环境领域取得了最先进的声音分类 (ESC) 任务新成果,优于其他方法在UrbanSound8K上达到 90.07% 的准确度,在ESC-50 数据集上达到 97.15%。此外,它还在相同数据集的零样本 ESCtask 中设置了新基线(分别为 68.78% 和 69.40%)。最后,我们还评估了所提出模型的跨模态查询性能以及完全和部分训练对结果的影响。
代码下载:https://github.com/AndreyGuzhov/AudioCLIP
论文下载:https://arxiv.org/pdf/2106.13043v1.pdf
内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢