
论文标题:Early Convolutions Help Transformers See Better
论文链接:https://arxiv.org/abs/2106.14881
作者单位:FAIR & UC Berkeley
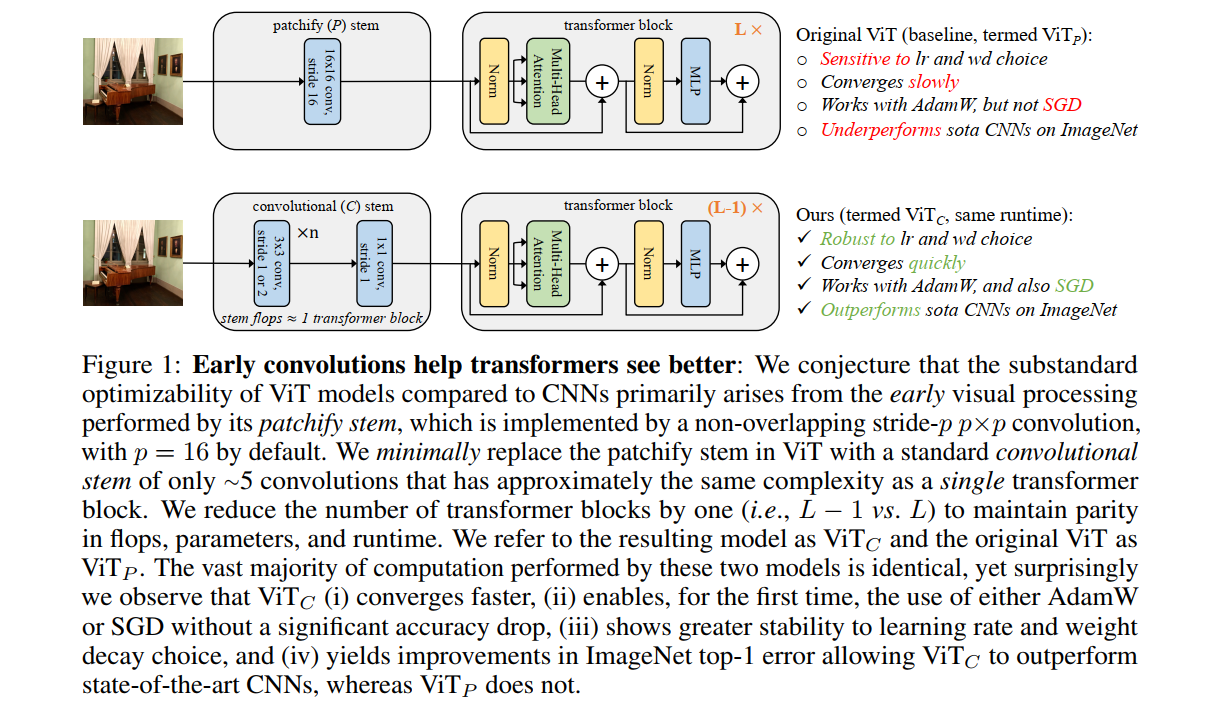
本文证明在 ViT 中使用卷积模块可显著提高网络的健壮性和峰值性能,标准或者轻量级卷积stem都可以有帮助!
视觉Transformer (ViT) 模型表现出低于标准的可优化性。特别是,它们对优化器的选择(AdamW 与 SGD)、优化器超参数和训练计划长度很敏感。相比之下,现代卷积神经网络更容易优化。为什么会这样?在这项工作中,我们推测问题在于 ViT 模型的 patchify 词干,它是通过应用于输入图像的 stride-p pxp 卷积(默认为 p=16)实现的。这种大内核加大步幅卷积与神经网络中卷积层的典型设计选择背道而驰。为了测试这种非典型的设计选择是否会导致问题,我们分析了 ViT 模型的优化行为及其原始 patchify 词干与我们用少量堆叠 stride-2 3x3 卷积替换 ViT 词干的简单对应物。虽然两种 ViT 设计中的绝大多数计算是相同的,但我们发现早期视觉处理的这种微小变化会导致在对优化设置的敏感性以及最终模型精度方面明显不同的训练行为。在 ViT 中使用卷积stem可显著提高优化稳定性并提高峰值性能(在 ImageNet-1k 上提高约 1-2% 的 top-1 精度),同时保持flops和运行时间。可以在广泛的模型复杂性(从 1G 到 36G flops)和数据集规模(从 ImageNet-1k 到 ImageNet-21k)中观察到改进。这些发现使我们提出为 ViT 模型使用标准的轻量级卷积模块作为与原始 ViT 模型设计相比更健壮的架构选择。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢