标题:罗切斯特大学、字节|Audiovisual Singing Voice Separation(视听歌声分离)
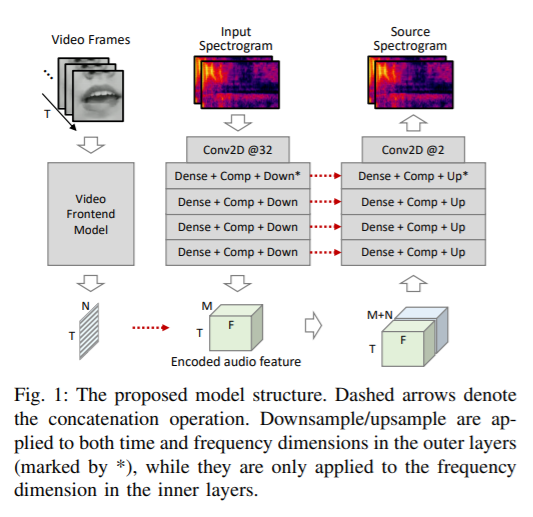
简介:将歌曲分为人声和伴奏组件是一个活跃的研究课题,近年来见证了深度学习技术使用监督训练的性能提升。我们建议将与歌手的声乐活动相对应的视觉信息应用于进一步提高分离的声音信号的质量。该视频前端模型接受嘴巴运动的输入并融合它进入基于音频的分离框架的特征嵌入。方便网络学习视听相关在歌唱活动中,我们添加了与歌唱活动无关的额外声音信号:训练期间嘴巴运动到音频混合。我们创造两个视听歌唱表演数据集,用于训练和评估,分别是从在互联网上挑选出来的试听录音中,以及在房子里的录音记录。提出的方法在分离质量方面优于基于音频方法。这个优势特别当伴奏中有和声时明显,这对纯音频方法提出了巨大挑战。
论文下载:https://arxiv.org/pdf/2107.00231v1.pdf
内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢