标题:伯克利|CLIP-It!Language-Guided Video Summarization(剪辑吧!语言引导的视频摘要)
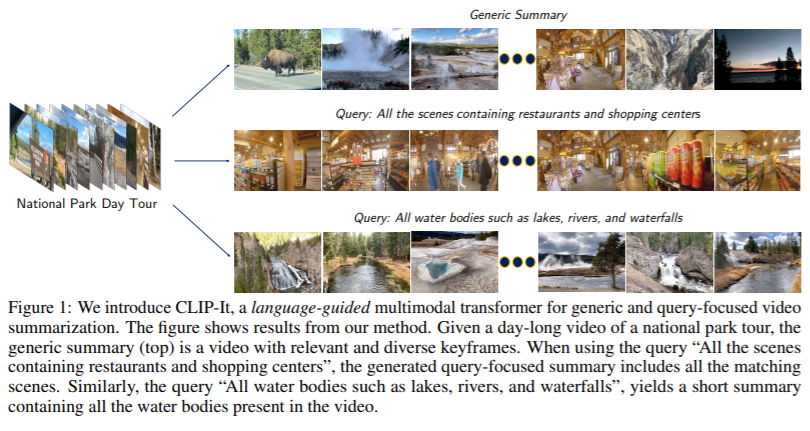
简介:通用视频摘要是视频的删节版,它传达了整个视频故事和特色最重要的场景。然而场景的重要性视频通常是主观的,用户应该可以选择自定义通过使用自然语言来指定对他们来说重要的内容。更多,现有的全自动通用摘要模型尚未开发可用的语言模型,可以作为显着性的有效先验。这工作介绍了 CLIP-It,这是一个单一的框架,用于解决通用和以查询为中心的视频摘要,通常在文献中单独处理。我们提出一种语言引导的多模态转换器,可以学习对帧进行评分在基于它们相对于彼此的重要性及其相关性的视频中使用用户定义的查询(用于以查询为中心的汇总)或自动生成密集视频标题(用于通用视频摘要)。我们的模型可以是通过没有地面实况监督的训练扩展到无监督环境。我们在这两个标准上都显着优于基线和先前的工作视频摘要数据集(TVSum 和 SumMe)和一个以查询为中心的视频摘要数据集 (QFVS)。特别是,我们在转移设置,证明了我们方法的强大泛化能力。
代码下载:https://github.com/medhini/clip_it
论文下载:https://arxiv.org/pdf/2107.00650v1.pdf
内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢