
PLOME: Pre-training with Misspelled Knowledge for Chinese Spelling Correction
- 任务介绍

中文拼写纠错也叫错别字纠错,目标是识别给定文本中的错别字并对其进行纠正。上图展示了一个例子,其中标红的是错别字,标绿的是改正字。文本中错别字的数量是不定的,可能没有错别字,也可能有多个错别字。
- 研究动机
中文纠错主要有两类错误:近音错误(phonological error)和形近错误(visual error),其中近音错误是指读音相同或相近的汉字误用,形近错误是指字形相近的汉字误用。图1展示了两类拼写错误的例子。

图1:中文拼写错误示例
语言模型对中文纠错来说非常重要,无论是传统的pipline纠错(基于单向LM)还是近两年兴起的end2end纠错模型(基于BERT,masked LM)都离不开语言模型。然而,这些方法用到的语言模型在训练时完全没有考虑纠错任务,因此对于纠错任务来说这些语言模型并不是最优的。为了解决这个问题,我们提出了一种针对中文纠错的预训练语言模型PLOME,在预训练过程中建模纠错知识。
另一方面,中文拼写错误主要由近音字误用和形近字误用引起,因此汉字之间的读音相似性和字形相似性对该任务至关重要。已有方法主要通过混淆集建模这类知识,然而混淆集一般通过启发式规则或人工总结的方式构建,因此并不完备。为了解决这一问题,我们将汉字的拼音序列和笔画序列也作为模型输入,并分别用两个子网络来计算它们的表示向量,让模型可以自动学习任意两个汉字在读音和字形上的相似度。另外,为了让模型更好地学习读音和汉字之间的关系,预训练阶段同时优化汉字预测和拼音预测两个任务。
本工作的主要贡献总结如下:1)PLOME是第一个针对纠错的预训练语言模型,我们提出了一种基于混淆集的MASK策略让模型在预训练时学习到纠错相关的知识;2)PLOME将汉字的拼音序列和笔画序列作为输入,能够建模任意两个汉字的相似度;3)PLOME是第一个联合汉字预测和拼音预测的中文纠错模型。
- 方法
模型架构如下图所示,和BERT类似,我们通过优化MLM的损失对模型进行预训练(去除NSP任务)。
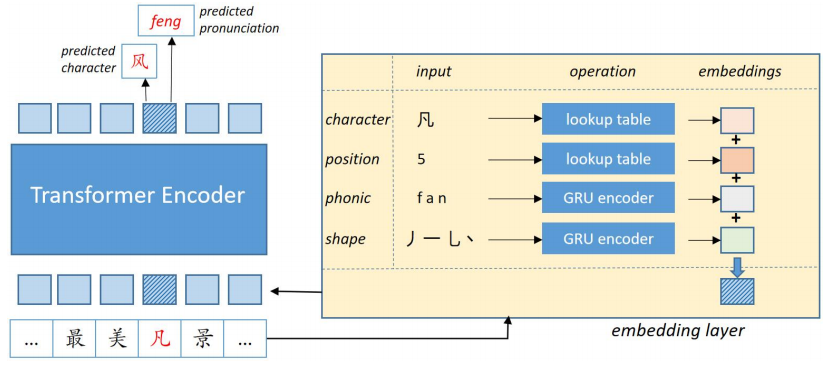
图2:PLOME模型框架图
为了在预训练阶段学习错别字知识,我们提出了一种基于混淆集的MASK策略。具体地,和原始BERT不同,我们并非使用特殊符号[MASK]去替换被选中的token,而是从token对应的混淆集中随机选择一个进行替换。我们有两类混淆集:拼音混淆集和形近混淆集。经过统计发现,文本中超过70%的错误是由于近音字引起的,因此在mask时我们让拼音混淆集有更大概率被选中。
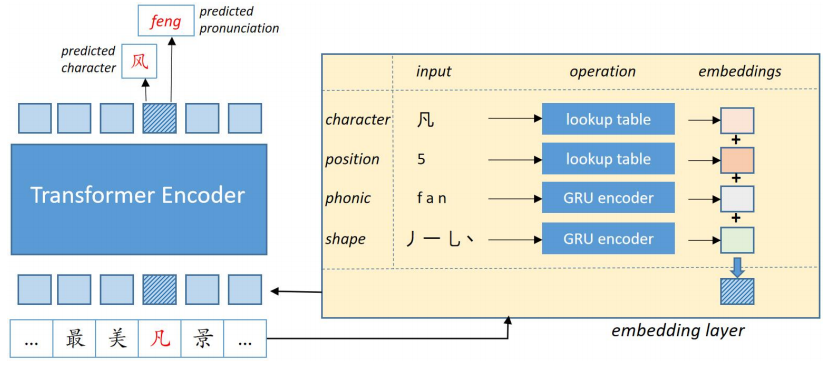
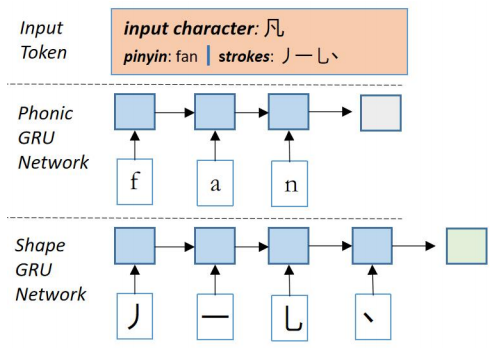
表1:基于混淆集的MASK策略示例 图3:拼音GRU和笔画GRU网络
为了建模汉字在发音和字形上的相似性,模型中引入了两个GRU子网络分别计算汉字的拼音向量和笔画向量,图3展示了这两个子网络的计算过程。模型的编码层和BERT base结构完全相同,由12层Transformer组成,向量维度768。如图2所示,模型为每个输入位置同时预测其真实汉字和拼音。
- 实验
本文实现了两个模型版本:
- PLOME: 本文提出的模型,模型结构在上文已经进行了详细的介绍。
- cBERT: PLOME的简化版本,去除拼音和笔画模块,保留基于混淆集的MASK策略。
为了证明模型的有效性,在公开数据集SIGHAN上进行了一系列实验。对比了最近几年的SOTA模型,实验结果如下:
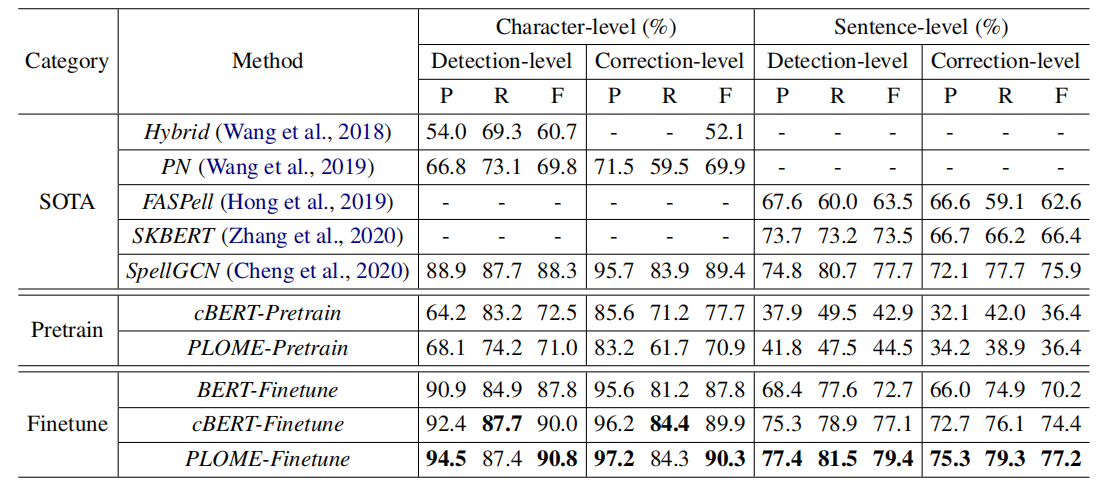
其中以Pretrain结尾的模型表示没有在SIGHAN数据上进行finetuning。从实验结果可以看到:1)本文提出的cBERT和PLOME,在不进行finetuning的情况下,仍然能够取得不错的效果,说明我们提出的预训练方法在预训练阶段能够很好地学习到纠错知识。2) PLOME效果比cBERT好,证明了拼音序列和笔画序列对纠错任务的有效性。3)经过finetuning,PLOME在各个指标上都显著高于所有SOTA模型。
- 总结
本文提出了一个针对纠错的预训练模型,在预训练阶段融入了纠错知识。另外,我们还显式建模了拼音和笔画序列,让模型能够自动学习任意两个汉字在发音和字形上的相似度。
代码和模型已开源:https://github.com/liushulinle/PLOME。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢