标题:达姆施塔特工业大学|A Survey on Data Augmentation for Text Classification(文本分类数据增强综述)
https://arxiv.org/ftp/arxiv/papers/2107/2107.03158.pdf
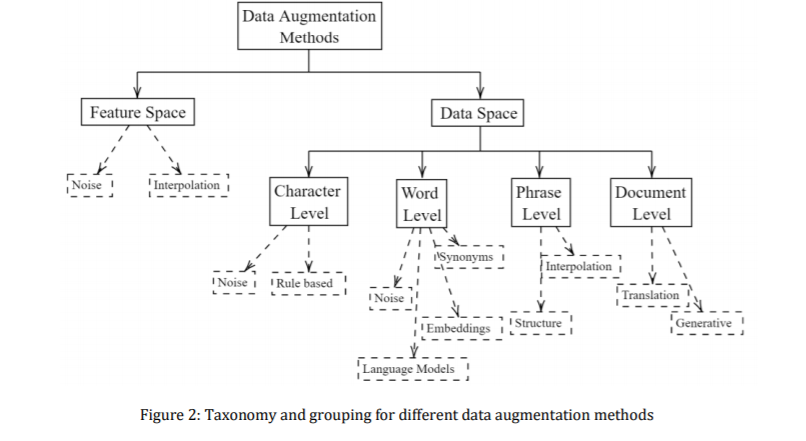
图1
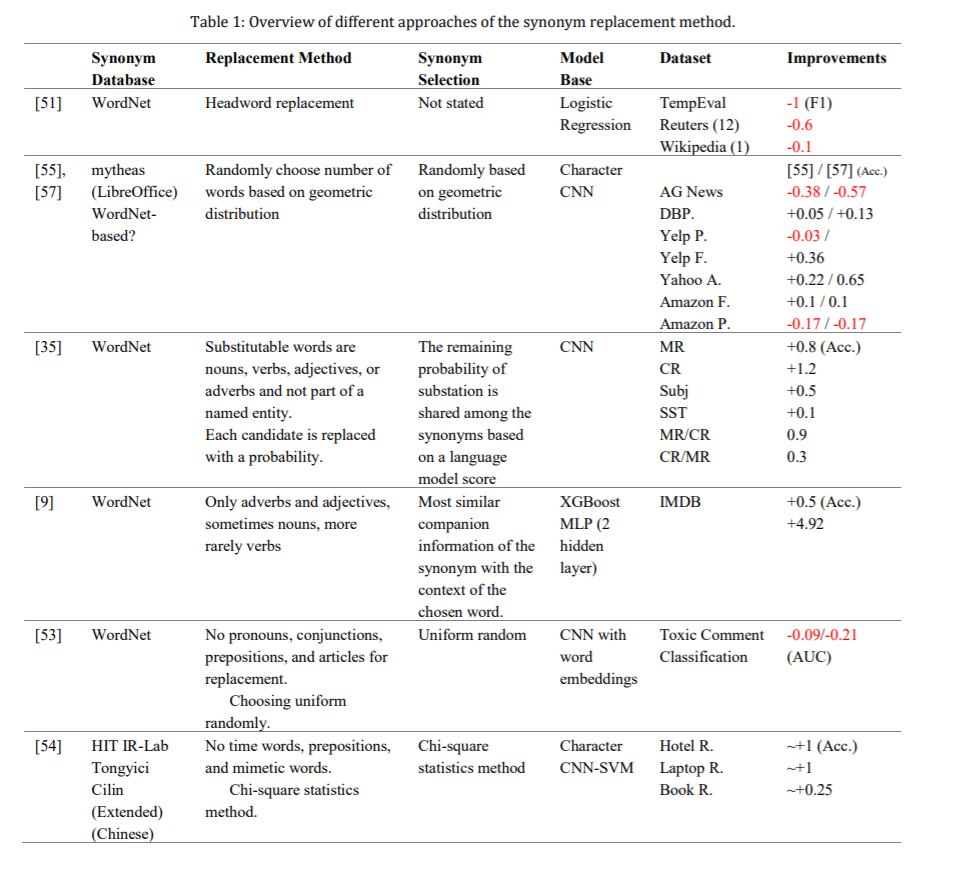
图2
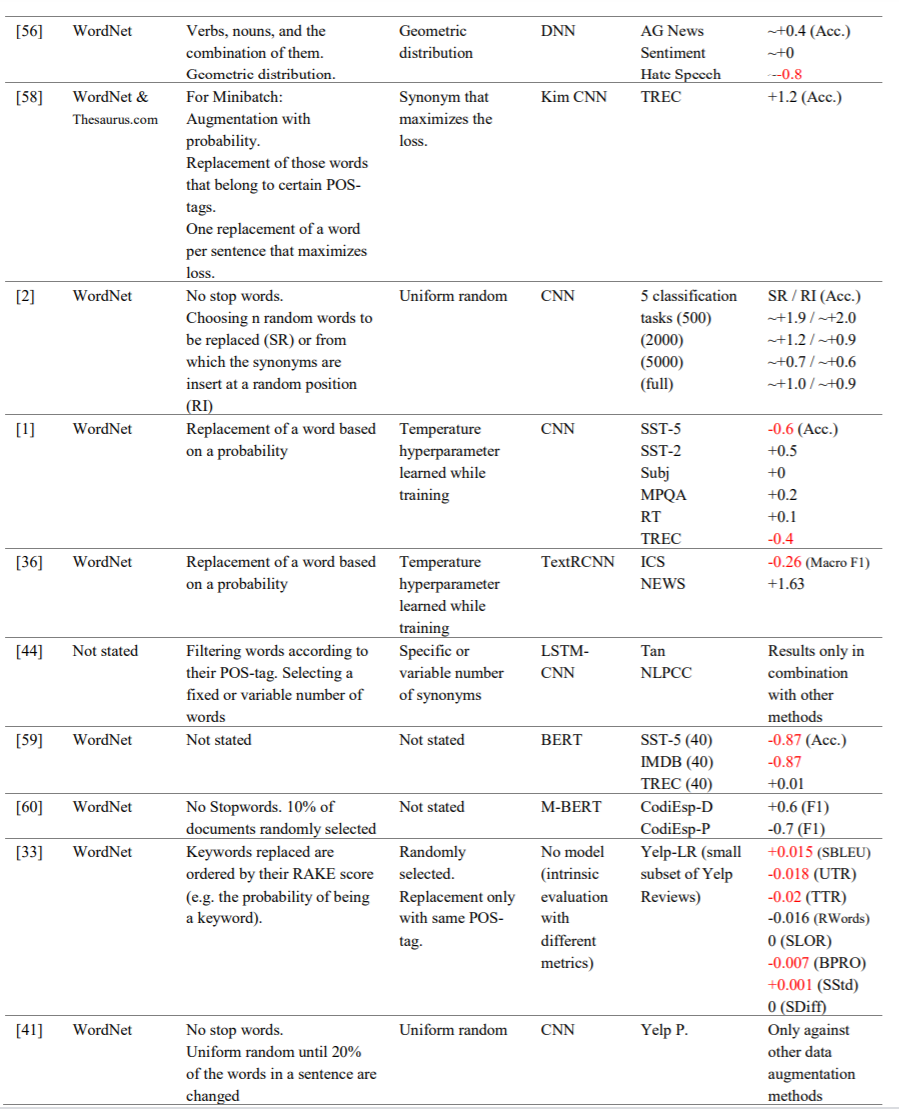
图3
内容中包含的图片若涉及版权问题,请及时与我们联系删除

https://arxiv.org/ftp/arxiv/papers/2107/2107.03158.pdf
图1
图2
图3
内容中包含的图片若涉及版权问题,请及时与我们联系删除
沙发等你来抢

评论
沙发等你来抢