
论文标题:Combiner: Full Attention Transformer with Sparse Computation Cost
论文链接:https://arxiv.org/abs/2107.05768
作者单位:斯坦福大学 & 阿尔伯塔大学
注意力模块的替代物!Combiner,它在每个注意力头中提供完整的注意力能力,同时保持低计算和内存复杂度,关键思想是将自注意力机制视为对每个位置嵌入的条件期望,并使用结构化因子分解近似条件分布,在多个图像和文本建模等任务上表现SOTA!
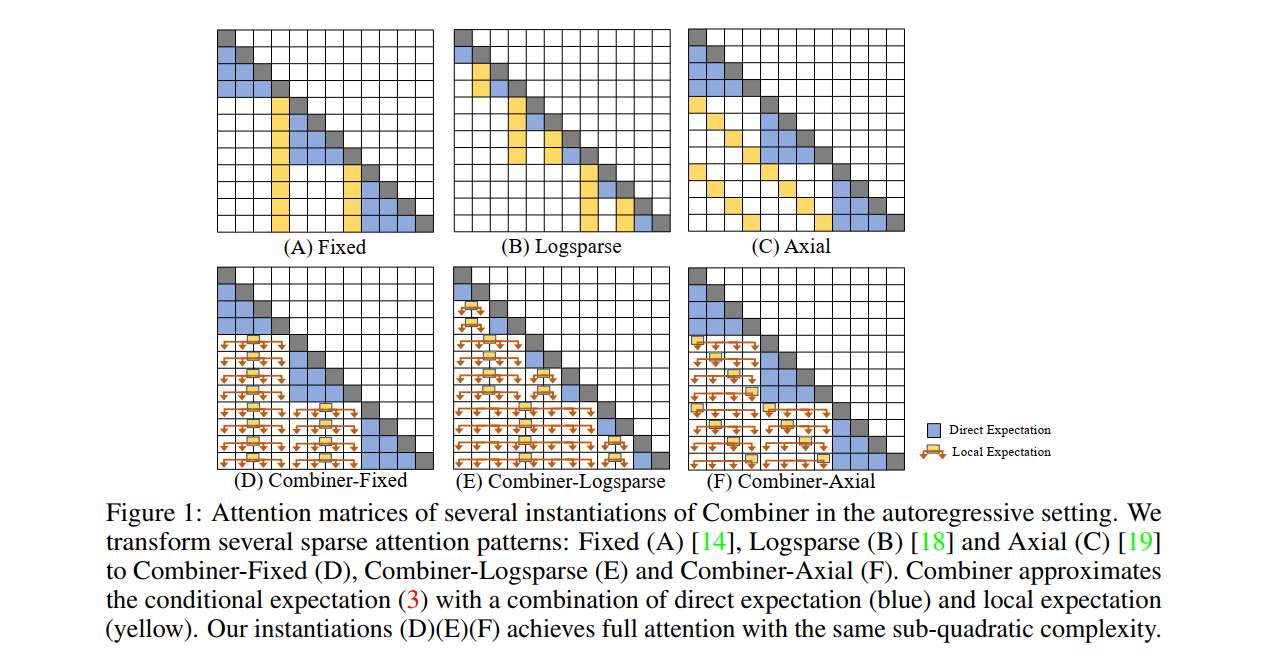
Transformer 提供了一类对序列建模非常有效的表达架构。然而,transformer 的关键限制是它们的quadratic memory和时间复杂度 O(L2) 相对于注意力层中的序列长度,这限制了在极长序列中的应用。大多数现有方法利用注意力矩阵中的稀疏性或低秩假设来降低成本,但牺牲了表示能力。相反,我们提出了Combiner,它在每个注意力头中提供完整的注意力能力,同时保持低计算和内存复杂度。关键思想是将自注意力机制视为对每个位置嵌入的条件期望,并使用结构化因子分解近似条件分布。每个位置都可以通过直接注意或通过对抽象的间接注意来注意所有其他位置,这也是对来自相应局部区域的嵌入的条件期望。我们表明,现有稀疏Transformer中使用的大多数稀疏注意力模式都能够激发这种分解的设计以实现充分注意力,从而产生相同的次二次成本(O(Llog(L))或 O(LL−−√)) . Combiner是现有Transformer中注意力层的直接替代品,可以在通用框架中轻松实现。对自回归和双向序列任务的实验评估证明了这种方法的有效性,在多个图像和文本建模任务上产生了最先进的结果。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢