标题:华为、悉尼大学|CMT: Convolutional Neural Networks Meet Vision Transformers(CMT:卷积神经网络相遇视觉变换器)
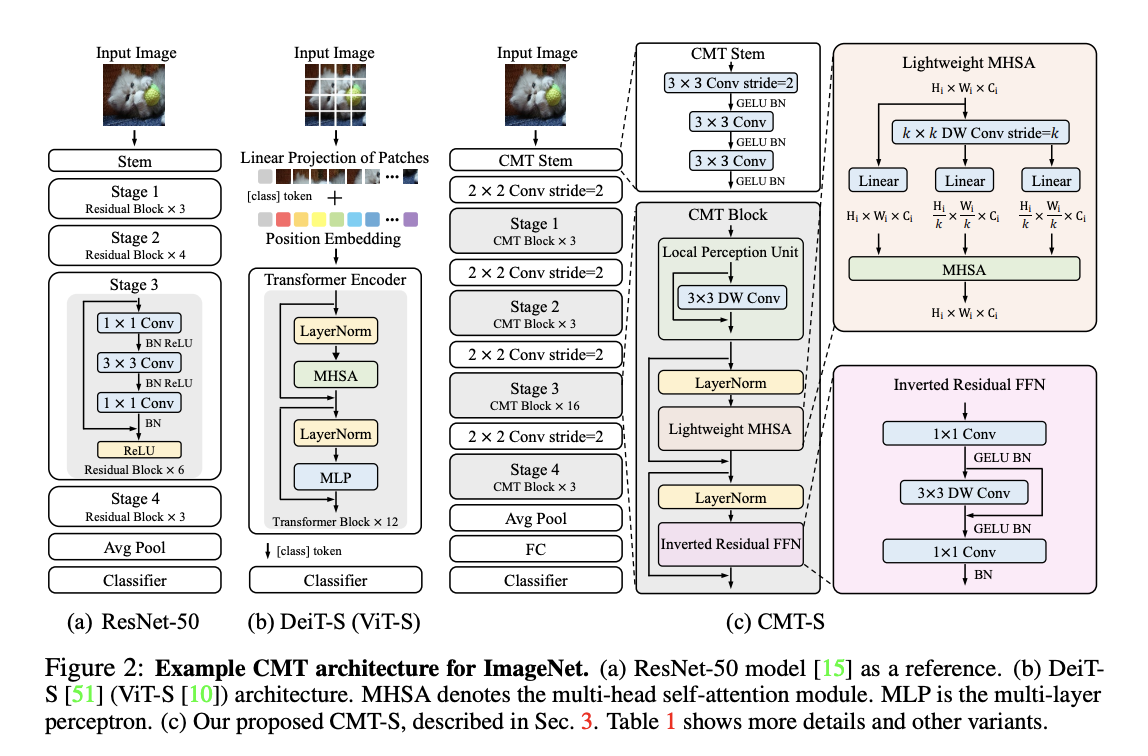
简介:由于视觉变换器在图像中捕获远程依赖项的能力,已成功应用于图像识别任务。然而,和现有的卷积神经网络 (CNN)相比,变换器的性能和计算成本仍然存在差距。在本文中,我们旨在解决这个问题并开发一个不仅可以超越规范的网络变换器,还有高性能的卷积模型。我们提出一种新的基于变换器的混合网络,利用变换器捕获远程依赖关系,并使用CNN对局部特征进行建模。此外,我们对其进行缩放以获得一系列模型,称为CMT,获得了很多比以前基于卷积和变换器的精度和效率更高的效果。特别是,我们的CMT-S在ImageNet上达到了83.5%的top-1准确率,虽然在FLOPs上比现有的DeiT和EfficientNet小14倍和2倍。提议的CMT-S在 CIFAR10 (99.2%) ,CIFAR100 (91.7%)、Flowers (98.7%) 和其他具有挑战性的视觉数据集上也有效,例如在COCO(44.3%mAP),计算成本要低得多。
论文地址:https://arxiv.org/pdf/2107.06263v1.pdf
内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢