
【标题】A Policy Gradient Algorithm for Learning to Learn in Multiagent Reinforcement Learning
【作者团队】Dong-Ki Kim, Miao Liu, Matthew Riemer, Chuangchuang Sun, Marwa Abdulhai, Golnaz Habibi, Sebastian Lopez-Cot, Gerald Tesauro, Jonathan P. How
【论文链接】https://arxiv.org/abs/2011.00382
【发表日期】2021.06.11
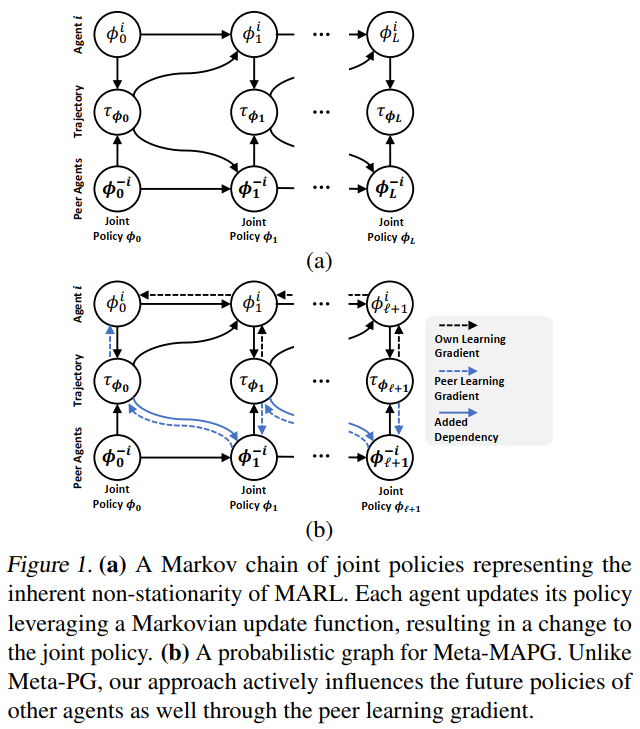
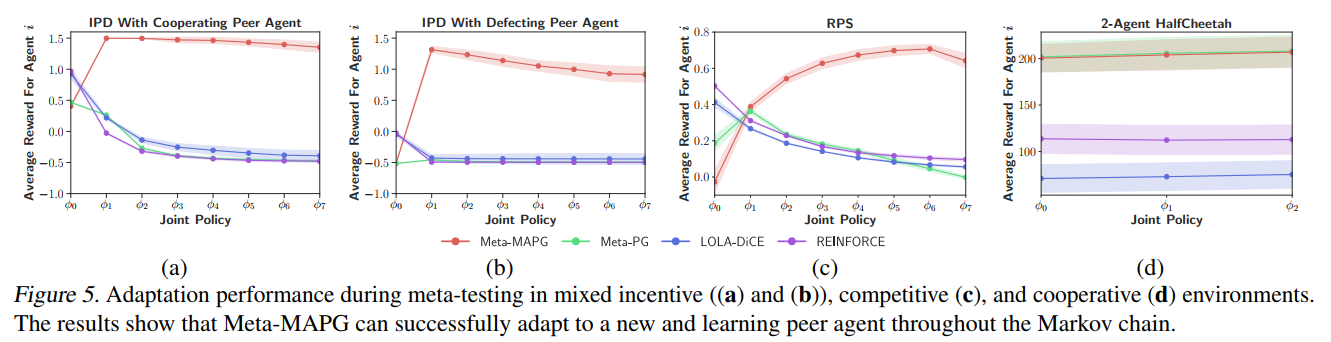
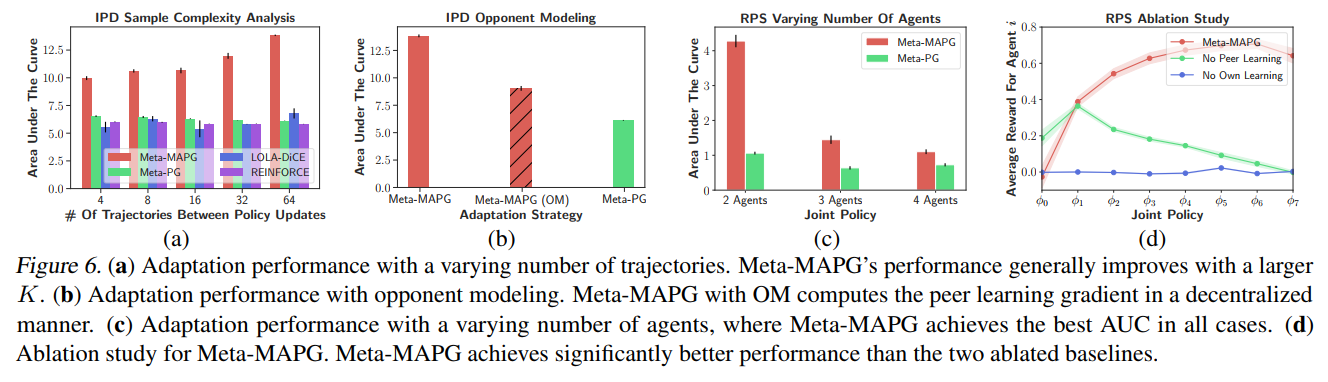
【推荐理由】如何在一个有着数个同时学习的智能体的共享环境中学习到有效行为一直是MARL的痛点问题,并且智能体的持续学习会导致经验的非静态分布。本文通过建模与主智能体和环境中其他智能体的非静态策略动态都相关的策略更新量,提出了一种可直接解释MARL环境中策略的非静态动态量的元多智能体策略梯度方法。本文的方法包含了相关方法中前序状态的所有关键特性。通过在多个MARL基准任务上的实验,作者证明了此方法可在非中心、协作式、竞争式的环境场景中都具有高效性能。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢