
【标题】Credit Assignment with Meta-Policy Gradient for Multi-Agent Reinforcement Learning
【作者团队】Jianzhun Shao, Hongchang Zhang, Yuhang Jiang, Shuncheng He, Xiangyang Ji
【论文链接】https://arxiv.org/abs/2102.12957
【发表日期】2021.02.24
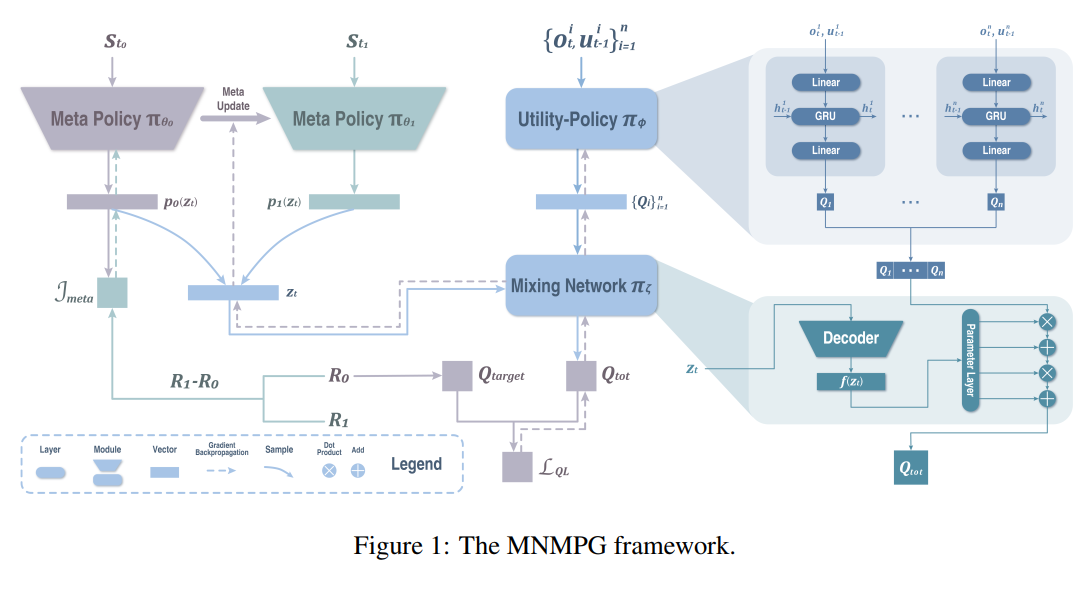
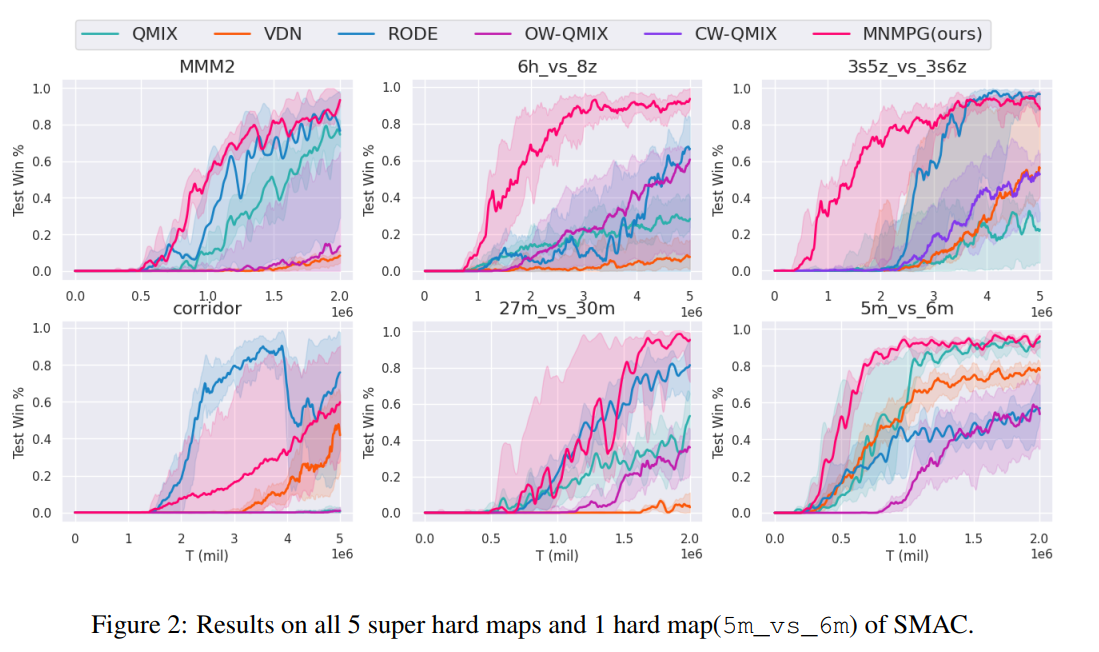
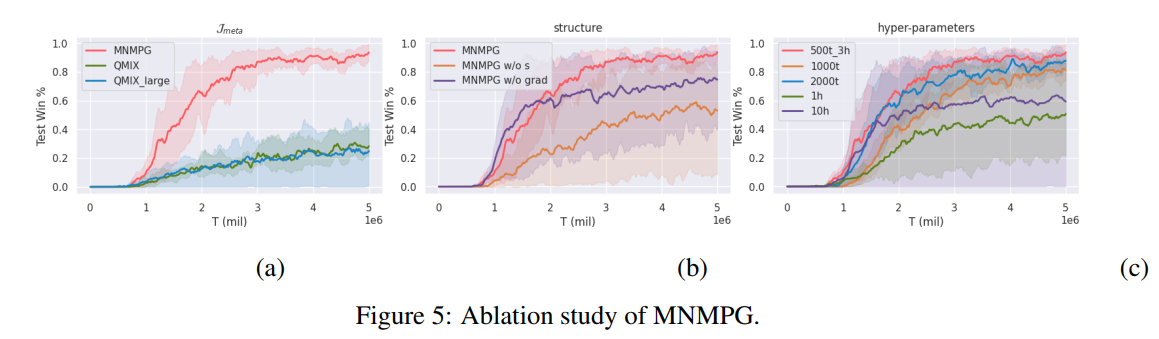
【推荐理由】非中心式执行(CTDE)&中心式训练是MARL环境中的一种,而回报分解是其中的一个关键问题。这种环境中的全局信息包含了所有智能体的状态与相关环境,以将Q值分解为单独的信用值。本文提出了一种可高度利用上述全局信息的基于元学习的、与元策略梯度相结合的混合网络,以获得具有更加精细的回报分解能力的全局架构。训练过程中,智能体会在全局架构下通过几个Q值更新来进行“练习行进”,“练习行进”之前和之后的回报差异对于全局架构的最终训练具有指导作用,可使得智能体的探索行为更好。并且,元学习方法使得本文算法可完全基于自我改进,不需要任何全局先验知识。

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢