
在平台上每天有超过3.7亿的用户会平均花费将近100分钟的时间观看短视频内容,观看直播,以及在平台上进行各种各样的消费。
在智源大会的智能检索与挖掘论坛上,快手副总裁王仲远博士介绍了团队在构建多模态Embedding模型方面所做的工作,提出将自监督与有监督学习相结合,辅助多种模型优化方法,更好地实现了短视频的内容理解和个性化推荐,进而为未来短视频平台的发展方向做出规划。
整理:路啸秋
编校:李梦佳

王仲远,博士,快手技术副总裁,MMU负责人。荣获2018年“《麻省理工科技评论》35岁以下科技创新35人”。曾在美团、Facebook、微软亚洲研究院任职,负责人工智能核心技术研发。王仲远博士在国际顶级学术会议及期刊发表论文50余篇,其中包括美国著名科学杂志《自然》人工智能子刊《Nature Machine Intelligence》,以及获得国际顶级学术会议ICDE 2015最佳论文奖。出版学术专著3部,获得美国专利5项,中国专利30余项。在NLP、知识图谱研究领域及搜索推荐等实际产品系统中均有丰富经验与产出。他的研究兴趣包括:自然语言处理、知识图谱、多模态、搜索推荐、深度学习、数据挖掘等。
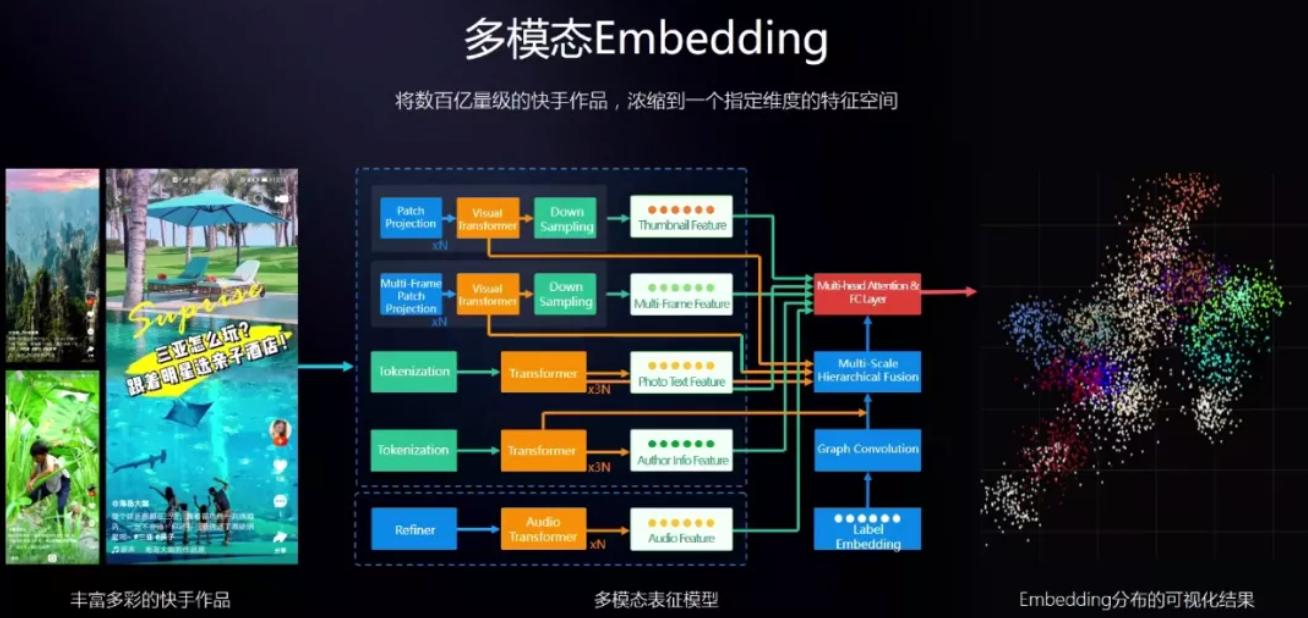
以快手平台为例,为了能够对这些丰富多彩的内容进行深度理解,并且通过推荐引擎个性化地分发给每一个用户,需要采用例如Embedding等技术将短视频映射到能够表达语义信息的语义空间。自从Embedding提出以来,越来越多的研究学者将其应用在自然语言处理、知识图谱、视觉音频图像等领域。

这些年在各种各样Embedding的工作当中,自监督学习凭借大数据的优势大放异彩,跟传统的有监督学习的方式相比,自监督学习可以利用互联网上的大数据以及各个APP里面用户上传的真实的海量数据,所以能达到一个模型预训练以及特征提取的目的。但是,它也面临非常大的挑战,就是因为缺乏确切的任务以及监督信号,所以会使得它在某些维度上,虽然是可解释的,但是与具体任务的目标可能是无关的。
当单纯采用自监督Embedding进行检索,如下图所示在介绍佳能相机的特性时,通过自监督Embedding确实关注到了黑色的背景以及构图的情况,但是却离这个视频的语义信息等理解有些许偏离。我们的真实想法是更希望能够在平台上检索出其他的佳能相机开箱视频、评测、展示等等。因此,需要有一种新的范式,将自监督学习与有监督学习进行有机结合。

为了帮助Embedding学习到视频的语义内容,王博士及其团队提出采用群体智慧作为监督信号,从而辅助自监督Embedding。群体智慧包括Hashtag、搜索Query以及用户评论。
01
在快手平台的短视频当中,大家通常会用一些话来描述短视频的内容。在描述中,很多用户都会加上“#”与文本,这样的描述语言被称之为Hashtag。Hashtag是短视频内容创作者自己认为的关键字词,能够很好的表达关键词或者核心的语义信息。Hashtag同时还具有以下几个特点:
1、取之不尽。过去一整年平台上Hashtag的数量总共有5000余万,覆盖了大约17%的作品。
2、相对于分布而言是比较均衡的,内容基本反映内容的分布情况。
3、有比较高的准确率。Hashtag与作品的相关性在最原始的时候大概是65%左右,通过词库的清洗并且加强规则和策略之后,可以使得相关性达到89%,这样做预训练的时候就是基本可用的。
02
搜索是用户对其感兴趣或需求进行主动探索的行为,搜索数据中不仅包含大量的有用query,还有用户点击等行为作为搜索结果的反馈,是一路优良的内容理解信号。
如果一个用户对儿童的装修房比较感兴趣,那么他就会搜索包含儿童装修房字眼的Query,搜完之后就会点击相关的视频。有些不感兴趣或者不相关的视频点完会立刻返回,但有些感兴趣的视频用户会进行浏览。过去一年全站的搜索行为超过了千亿。即使经过清洗也可以获得百万的图文匹配对。
03
用户评论相对于Hashtag和搜索Query来看,整体上会比较长。评论区是用户分享对作品的想法和观点的聚集地。每个作品都可以有多个评论,高质量作品的平均评论数目会超过上千条;不同于Hashtag由作者生成,评论直接由用户生产,真实反映了用户对作品的理解;同时评论是从多个角度刻画作品内容、描述作品主题。针对非结构化的用户评论的分析与解读,对于更好地理解作品内容大有裨益。
为此,团队构建了如下所示的多模态Embedding训练模型,最底层是多模态的输入,包括视觉、文本、音频等等信号的输入。在此之上,是各个模态的训练模型以及模态融合的模型,最顶层是一个多任务的预训练模型。
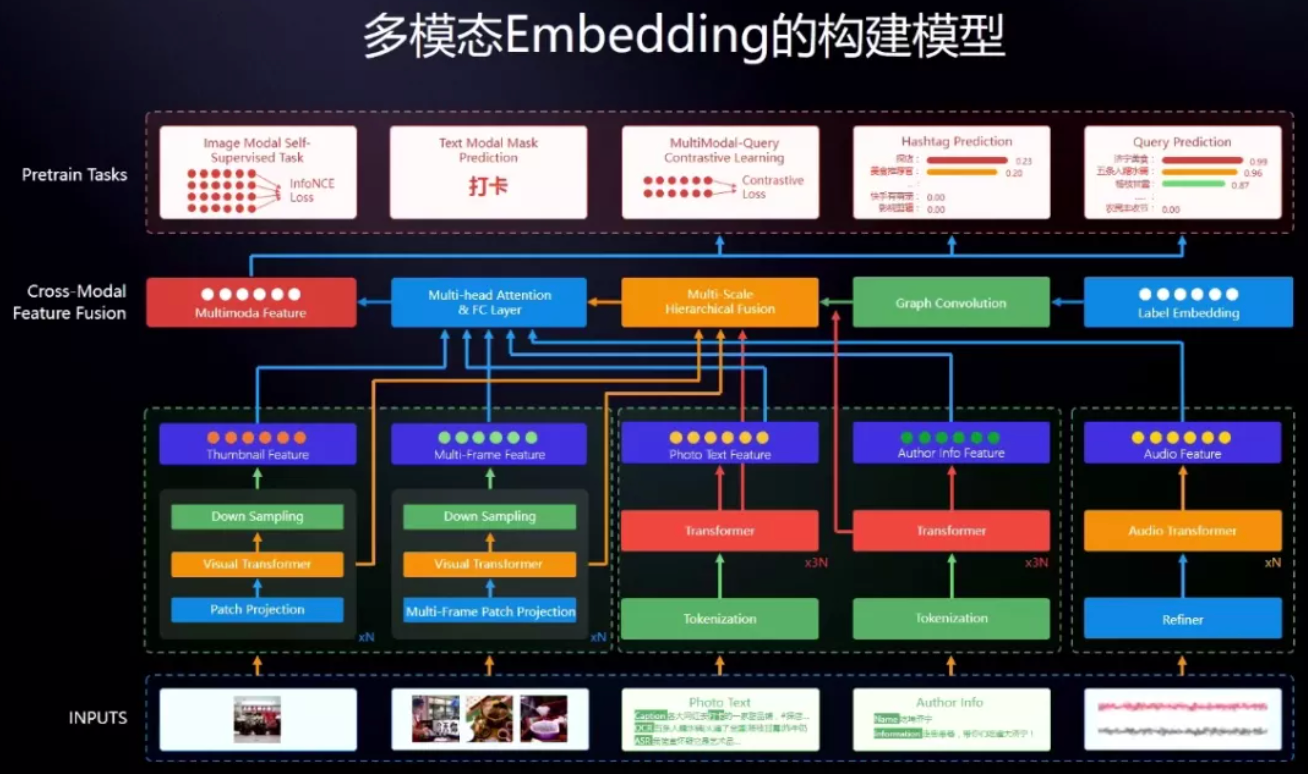
为了能够实现更优异的模型表现性能,团队对模型采取了多重优化方案,包括采用视觉Transformer、多尺度特征融合以及特征层融入图卷积神经网络等模型优化方法。
1
视觉Transformer
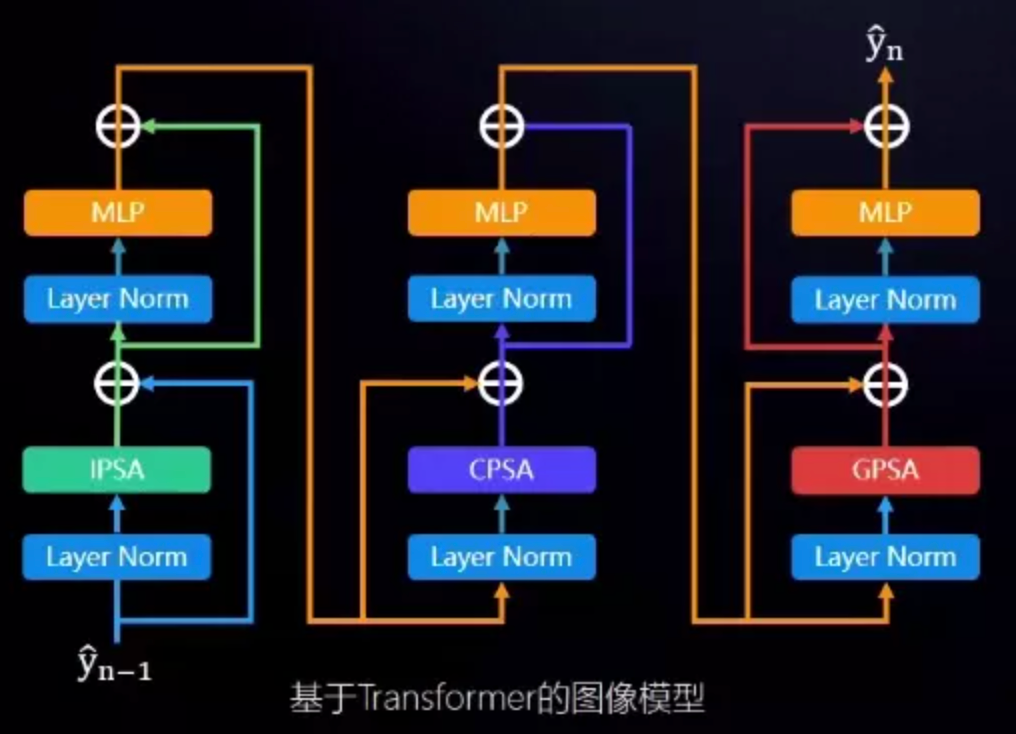
在模态训练方面,针对视觉使用了自研的Transformer结构作为Backbone,对比CNN更能捕捉局部特征和全局特征的关系,同时能保证图文模型同构,为后续多模态的融合打下了非常坚实的基础。
1
多尺度特征融合
在模态融合方面,传统的方法一般是进行简单的拼接和矩阵的运算,而模型中采用的是多头注意力机制的方式进行模态的融合,同时会引入多尺度的特征融合策略代替顶层融合,从模型底层开始对不同尺度中得到的图文特征进行Transformer,逐层递进,使得底层多模特征更充分地参与模型的表达。
2
融入图卷积神经网络
除了图文多尺度融合,模型还在特征层融入了图卷积神经网络。通过多模态预训练的Text Encoder,计算标签的词向量作为标签表示,并利用标签关系构建图卷积神经网络,使得模型学习到更具有可解释性的向量特征。
在最顶层的多任务设计阶段,与其他的预训练模型一样,该模型同样引入了自监督学习作为模型训练的任务。在图像模态的自监督方面,采用了SimCLR v2训练范式,构造正负样本对,通过InfoNCE loss监督图像模态学到更好的表征。在文本Mask Prediction方面,不同于随机mask的方式,模型采用预训练模型找到文本中权重较高的部分作为关键词,进行关键文本的预测。
在有监督任务中,模型主要关注多标签分类任务。利用Hashtag和搜索Query等监督信号建立多标签分类任务,为了兼顾标签的频次与新鲜度,引入TF-IDF加权的方式,优化了多标签的交叉熵损失。
通过上述所提及的优化方案,可以构建一个多模态Embedding的框架,从而能够将短视频映射到一个具有表征其语义信息的空间特征当中。
有了多模态的Embedding,就可以使用向量检索平台进行检索。通常在进行向量检索的时候会使用欧式距离等方式来计算。单个计算的时间复杂度很低,但是考虑到平台上的量级非常大。如果要做精确计算,整个及时检索成本可能会高达30亿美金,但通过定式向量的方法,可以将成本压缩到300台GPU的机器就足以完成近似检索。整个向量检索平台如下所示,自底向上包括IO层,计算层,调度层和接入层。
多模态Embedding可被用于短视频生产的各个环节,从生产阶段辅助用户只能创作,到冷启动阶段的优质作品流量扶持,再到基于Embedding检索的长期兴趣推荐。通过Embedding串联起来的短视频生态,帮助一个新作品拍摄的更加有趣,被更多可能喜欢它的人看到,最终反哺生产侧,带动用户的生产热情。
辅助进行视频创作
基于多模态Embedding预训练模型,利用知识蒸馏得到轻量模型,能够实现作品内容的实时理解。过去的半年时间,在话题标签推荐任务重,带动了站内带话题标签作品量提升超过57%,在包括智能配乐、RAP生成、封面文案生成在内的生产侧任务中被广泛应用。
帮助优质视频尽快获得流量
一个视频创作初始是没有用户行为特征的,因此必须要依靠于对于视频本身的内容理解来进行预估。多模态的Embedding再加上Fine-tuning可以预估一个视频获得的流量,从而帮助一个优质的视频尽快的获得比较好的流量。如果这个视频在预估的流量上有比较好的表现的话,就能够进入到整个平台的全流量的分发,从而帮助优质作品获得更多的曝光。
将内容理解与推荐结合
高质量的多模态Embedding为基于内容理解的推荐提供了新的可能性,在基于内容理解的推荐场景中,Embedding被用于从用户消费历史中精准检索与当前要预估作品最相关的作品,并从检索回的作品中预估出用户对要预估作品的感兴趣程度;进而通过长短期兴趣结合的方式,大幅度提升了人均视频观看时长等核心指标。
相关视频
除了跟推荐系统结合以外,多模态Embedding也可以作为一项产品功能来推出。当用户看一个视频的时候,可以通过相关视频浏览到跟这个视频在语义上非常相似的其他视频。
实体检索
除了视频级的Embedding检索以外,实体检索也被提上日程。如果一个用户喜欢视频中的鞋子,就可以通过检索的能力找到平台上同款的鞋子,并且可以直接下单。除了商品以外,团队也正在构建宠物识别、植物识别、品牌识别、IP识别等等,希望可以做到万物检索,去识别千亿级视频中的实体。
为了实现万物检索的目标,王博士提出了未来发展的几个方向:
首先,更大规模的模型与在线学习,争取在2021年底将训练框架扩增至百亿量级参数。强化模型对增量样本的拟合能力;
其次,跨域内容理解Embedding,在不需要显示用户画像的前提下完成用户兴趣的跨域映射,从而为用户提供更精准的推荐服务;
最后,向量检索平台的高级特性提升,包括多模检索中的精准语义检索、知识推理以及系统效率提升。
深刻改变人类社会生活的非渐进式创新,需要依靠极具创造力的人才,围绕共同愿景,在不同学科相互融合、发明与发现循环的过程中开展紧密协作。智源社区的目标,是构建高度合作的科学研究社区,在前所未有的规模和领域中,充分发挥成员的协同效应。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢