
7月8日,中文语言理解权威评测基准CLUE公开了中文小样本学习评测榜单最新结果,阿里云计算平台PAI团队携手达摩院智能对话与服务技术团队,在大模型和无参数限制模型双赛道总成绩第一名,决赛答辩总成绩第一名。
比赛数据集总体特点如下:
-
小样本:训练集和检验集均为每个类别16shot,考验算法在小样本情境下的鲁棒性。
-
泛化性:任务特征差异明显,需要模型有较好的泛化能力。
-
无标签数据:多数任务提供了数量可观的无标签数据,可以尝试continued pretrain和self-training。
-
通用领域数据的从头预训练:借助PAI-Rapidformer提供的各种加速策略以及预训练套件,我们从头预训练了3亿量级和15亿量级的中文预训练模型,预训练过程采用融入知识的预训练算法。
-
多任务的继续预训练:目的是进一步强化双句匹配任务(OCNLI, BUSTM, CSL)的Performance。我们将分类任务转化为文本蕴含任务,使用文本蕴含数据进行Continued Pretrain,例如 [CLS]I like the movie[SEP]This indicates positive user sentiment[EOS] 。
-
针对每个任务进行小样本算法微调:选择PET(Pattern-Exploiting Training)作为下游微调的核心方法, 开发Fuzzy-PET算法,减少了PET算法标签词人工选择带来的波动,并且在任务上带来效果提升。同时使用了self-training 的半监督方法,在下游微调阶段利用上半监督学习。

1)激活检查点(Activation Checkpoint)
在神经网络中间设置若干个检查点(checkpoint),检查点以外的中间结果全部舍弃,反向传播求导数的时间,需要某个中间结果就从最近的检查点开始计算,这样既节省了显存,又避免了从头计算的繁琐过程。
2)梯度累积 (Gradient Accumulation)
以batch_size=16为例,可以每次算16个样本的平均梯度,然后缓存累加起来,算够了4次之后,然后把总梯度除以4,然后才执行参数更新,这个效果等价于batch_size=64。这是一种有效的增加Batch Size的方法。通过该策略可以将每个step的batch size扩充到很大,结合LAMB优化器会提升收敛速度。
3)混合精度训练(Mixed Precision Training)
采用混合精度训练的好处主要有以下两点:
-
减少显存占用,由于FP16的内存占用只有FP32的一半,自然地就可以帮助训练过程节省一半的显存空间。
-
加快训练和推断的计算,FP16除了能节约内存,还能同时节省模型的训练时间。具体原理如下图所示,核心是在反向传播参数更新的时候需要维护一个FP32的备份来避免舍入误差,另外会通过Loss Scaling来缓解溢出错误。
4)即时编译JIT
当PyTorch在执行一系列element-wise的Tensor操作时,底层Kernel的实现需要反复地读写访存,但是只执行少量的计算,其中大部分时间开销并不在计算上,而在访存读写上。比如,实现一个带有N个元素的Tensor的乘/加法Kernel,需要N次加计算,2N次读和N次写访存操作。我们称计算少, 访存次数多的Kernel为访存Bound。为了避免这种反复的读写,以及降低Kernel Launch的开销,可以采用Kernel Fusion。访存Bound的Kernel Fusion的核心原理是通过访存的局部性原理,将多个element-wise的Kernel自动合并成一个Kernel,避免中间结果写到内存上,来提高访存的利用率;同时由于多个Kernel合并成一个Kernel,Kernel launch开销也减少到了1次。
5)3D并行
3D并行策略指的是:数据并行,模型并行,流水并行三种策略的混合运用,以达到快速训练百亿/千亿量级模型的目的。该项技术最早由DeepSpeed团队研发,可以加速大模型的训练。
6)CPU Offload
反向传播不在GPU上计算,而是在CPU上算,其中用到的中间变量全部存储在内存中,这样可以节省下GPU的显存占用,用时间换空间,以便能放到更大尺寸的模型。
7)Zero显存优化器
ZeRO(The Zero Redundancy Optimizer)是一种用于大规模分布式深度学习的新型内存优化技术。ZeRO具有三个主要的优化阶段:
-
优化器状态分区(Pos) :减少了4倍的内存,通信容量与数据并行性相同;
-
增加梯度分区(Pos+g) :8x内存减少,通信容量与数据并行性相同;
-
增加参数分区(Pos+g+p) :内存减少与数据并行度和复杂度成线性关系。
本次发布使用了最新的阿里云EFLOPS AI集群系统,使用NVIDIA A100 GPU和 100Gbps Mellanonx CX6-DX网卡,结合全系统拓扑感知的高性能分布式通信库ACCL 和 EFLOPS集群多轨网络能力,实现无拥塞通信,大幅加速了模型的训练速度。如下图所示:
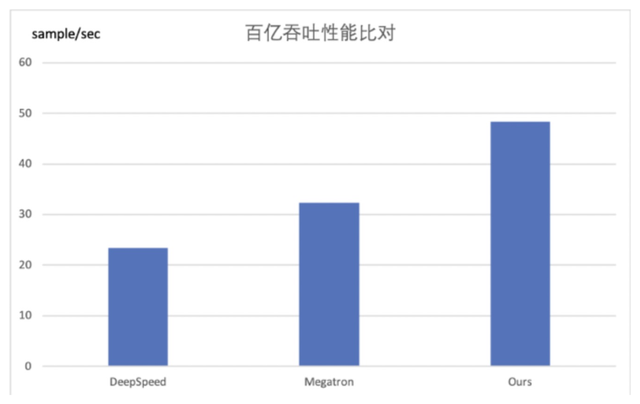
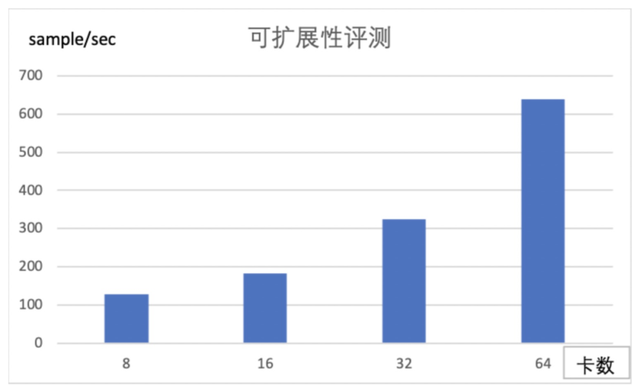
我们采用比BertLarge更大一点的单卡放不下的模型来做模型并行下的可扩展性评测。具体配置是 num-layers=24,hidden-size=2048,num-attention-heads=32,该模型的参数总量大约是1.2B。我们分别在8/16/32/64卡上进行来吞吐评测,从下图的指标来看,随着卡数的增加,吞吐几乎是近线性的提升。
-
大规模:5亿中文图谱知识,通过远监督获取2亿 Sentence-SPO Pair;
-
高质量:针对原始语料庞杂,存在大量冗余、噪声的问题,通过DSGAN知识降噪算法,精选上亿高质量Sentence-SPO,用于模型训练;
-
多样性:FewCLUE数据集除了通用领域,还包含电商、旅游、教育、金融等垂直行业,而这部分数据和知识比较稀缺,为此我们构建了一套高效的知识生产系统,能够对各类垂直行业的文档、网页进行自动三元组抽取,从而极大的提升了知识的丰富度。
-
Mention Detection:增强模型对核心实体Mention的理解;
-
Sentence-SPO joint Mask:将大规模文本数据及其对应的SPO知识同时输入到预训练模型中进行预联合训练,促进结构化知识和无结构文本之间的信息共享,提升模型语义理解能力;
-
SPO Margin Magnify:设计对比学习的预训练任务,拉开Sentence相关SPO与无关SPO语义间隔,使其具备更强的语义区分能力。
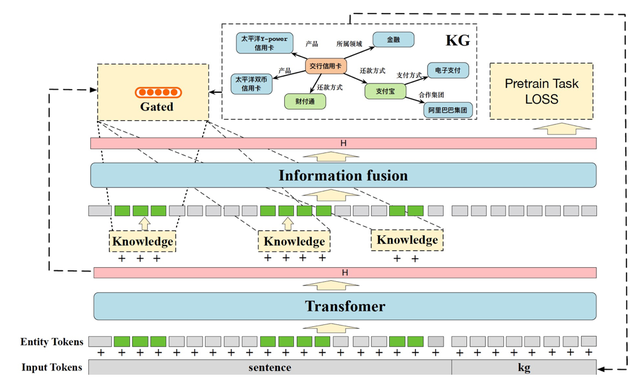
1)动机
NLP任务中,常见的做法是根据当前输入的自然语言进行建模,但是这样通常用到的信息只有当前字面局部信息。这和人类在理解语言的时候具有明显差别,人类会用到我们之前学习到的知识辅助理解。人类会利用这些外部知识来加强自己的理解,如果没有额外的知识,比如接触到我们一个不熟悉的领域,我们也很难完全理解语义。而目前NLP常见做法只利用了输入信息,没用利用外部知识,理解层次偏低。
现实中知识是庞大且繁杂的,需要针对性的采样知识,减少引入无关的知识,最大化知识的收益。
设计一种新颖的Gated机制,先对句子进行编码,再通过GCN聚合出子图信息,通过门控机制,控制信息的流入;在预训练阶段,通过设计最大化知识增益目标函数,让模型更好的学习到有价值的信息。
在特定小样本任务学习阶段,我们对Pattern-Exploiting Training(PET)算法进行了改进,引入了Fuzzy Verbalizer Mapping机制。举例来说,在经典的PET算法中,对于FewClue的任务OCNLI,我们设计了如下模板:“其实我觉得你不懂球啊”和“你不懂篮球”的关系是[MASK][MASK]。
对于输出的Masked Language Token(即Verbalizer),如果预测结果为“相关”,我们将其映射为类别标签“entailment”;如果预测结果为“无关”,我们将其映射为类别标签“neural”; 如果预测结果为“相反”,我们将其映射为类别标签“contradiction”。利用Verbalizer到类别标签人工映射,PET实现了对文本分类任务的建模。在Fuzzy Verbalizer Mapping机制中,我们假设多个Verbalizer可能对某一个类别标签有映射关系,从而进一步提升模型在小样本学习过程中的泛化性。参考先前的例子,我们设计三组标签词:相关,无关,相反/蕴含,中性,矛盾/包含,中立,反向。训练时每一条样本使用多组标签词输入,在推理时每个类别计算所有候选词的预测概率并相加,最终选择总概率最高的类别。如上述例子,若预测“相关”、“蕴含”、 “包含”的概率和大于预测“无关”、“中性”、“中立”或预测“相反”、“矛盾”、“反向”的概率,则预测结果为“entailment”。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢