
论文题目:Zero-shot Adversarial Quantization
论文来源:CVPR2021 oral
论文作者:Yuang Liu , Wei Zhang, Jun Wang
作者单位:华东师范大学
下载链接:https://arxiv.org/pdf/2103.15263.pdf
代码地址:https://github.com/FLHonker/ZAQ-code
为了在无法获得原始数据情况下实现模型量化,现有方法采用训练量化或BN层统计量引导生成的合成样本对网络进行微调,但两者存在性能低下的问题,本文
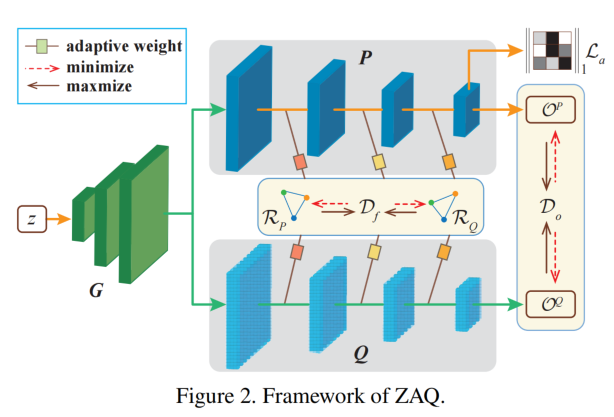
预测结果可能是相似的,使得负的KLD太小而无法优化。因此我们采用 L1 损失来更直接地测量输出损失:![]()
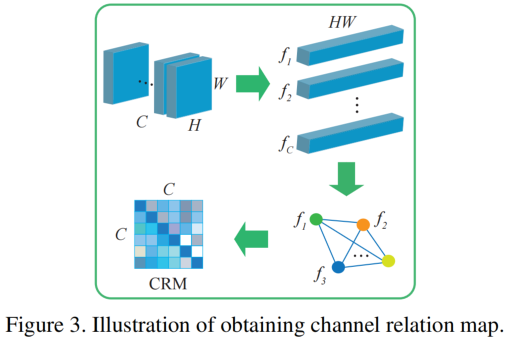
的启发,我们考虑不同通道之间特征图的相似关系,利用CRM捕获同一个模型的同一层中不同通道之间的关系。它既能消除不同数值跨度的特征图的影响,又能代表样本的高维特征。定义中间层内部差异为:![]() .
.
L是层数,R表示提取出的通道关系图,![]() 表示该层的自适应权重,
表示该层的自适应权重,

式中 EMA为指数移动平均,T为每个epoch的训练步长,L为ZAQ所利用的层数。通过这种方式,。此外,为了避免在长期训练中打破平衡,![]() 需要在新的epoch开始时重新以1/L初始化。
需要在新的epoch开始时重新以1/L初始化。
误差估计阶段(训练生成器)![]()
知识迁移阶段(训练学生)![]()
用![]() 表示网络P的最后一层卷积层提取的第i个通道激活图。那么激活正则化可以表示为:
表示网络P的最后一层卷积层提取的第i个通道激活图。那么激活正则化可以表示为:![]() 。根据直觉,高激活值意味着给定的输入示例和训练数据之间更好的匹配,因此训练生成器的损失表示为
。根据直觉,高激活值意味着给定的输入示例和训练数据之间更好的匹配,因此训练生成器的损失表示为![]()
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢