
【论文标题】UIBert: Learning Generic Multimodal Representations for UI Understanding
【作者团队】Chongyang Bai, Xiaoxue Zang, Ying Xu, Srinivas Sunkara, Abhinav Rastogi, Jindong Chen, Blaise Aguera y Arcas
【发表时间】2021/07/29
【机 构】谷歌、达特茅斯学院
【论文链接】https://arxiv.org/pdf/2107.13731v1.pdf
【代码链接】https://github.com/google-research-datasets/uibert
【推荐理由】SOTA多模态UI场景模型
为了提高智能设备的可及性并简化其使用,建立能够理解用户界面(UI)并协助用户完成其任务的模型至关重要。然而,UI的具体特点提出了独特的挑战,例如如何有效地利用涉及图像、文本和结构元数据的多模态用户界面特征,以及如何在高质量的标记数据不可用时实现良好的性能。为了应对这些挑战,我们引入了UIBert,一个通过对大规模未标记的UI数据进行新的预训练任务来学习UI及其组件的通用特征表征的基于Transformer的图像-文本联合模型。本文的核心思想是,用户界面中的异质特征是自我对齐的,也就是说,用户界面组件的图像和文本特征是可以相互预测的。我们提出了五个预训练任务,利用UI组件的不同特征之间以及同一UI中的不同组件之间的这种自我对齐。我们在九个真实世界的下游UI任务中评估了我们的方法,其中UIBert比强大的多模态基线的准确率提高达9.26%。
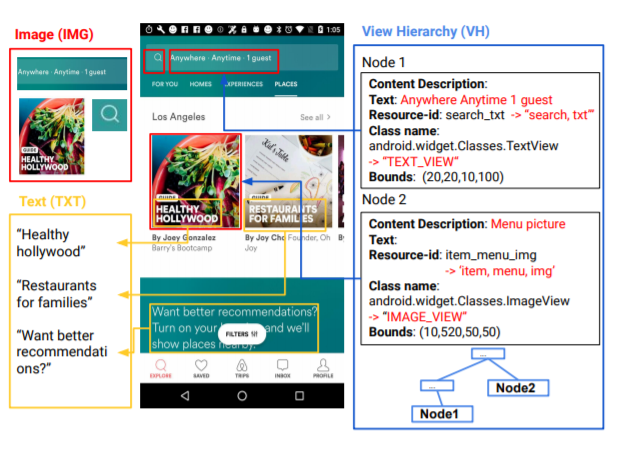
上图展示了UI界面的异质特征,主要包括图像,文本和结构数据。
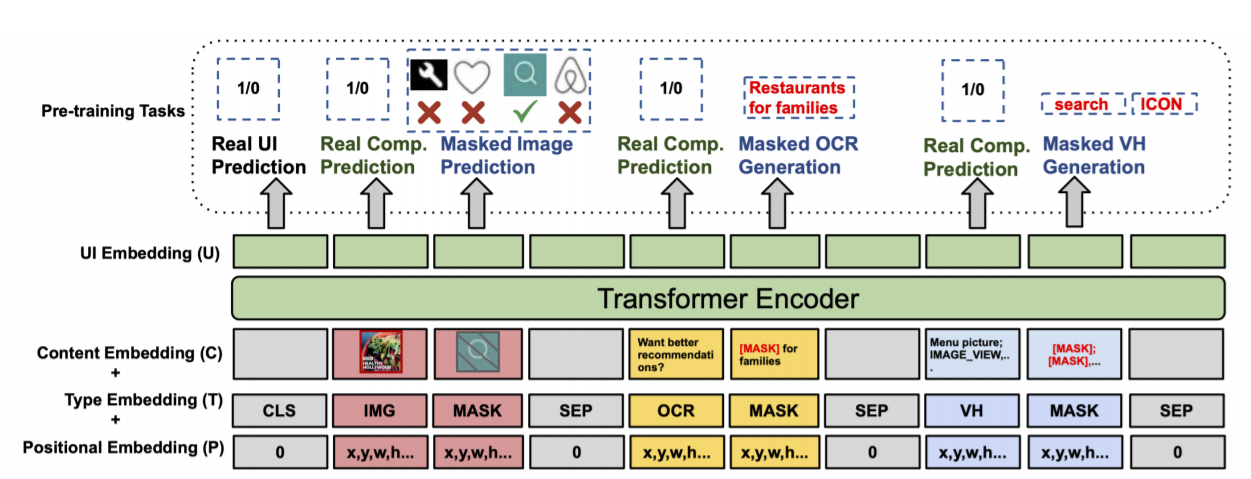
上图为UIBert概述,它将异质特征作为输入,内容、类型和位置嵌入被计算出来,并作为Transformer的输入进行汇总。输出的UI嵌入U,被用于预训练和下游任务。我们在预训练中随机选择一种类型的组件(IMG、OCR或VH)进行屏蔽,但为了节省空间,图中显示了我们在一个用户界面中屏蔽所有三种类型的情况。
5种预训练任务分别为:
- 真实UI预测,随机替换15%的UI元素创建假UI,任务为判断UI是真实的还是伪造的。
- 真实成分预测,任务为判断伪造UI中,伪造部分与剩余真实部分是否对齐。
- 遮蔽图像预测,随机遮蔽15%的图像输入,任务为用剩余的85%真实UI图像推断出遮蔽的部分。
- 遮蔽文本生成,根据UI组成预测15%遮蔽的原本的OCR文本。
- 遮蔽结构数据生成,遮蔽其中的内容描述和类别名,进行生成和预测。
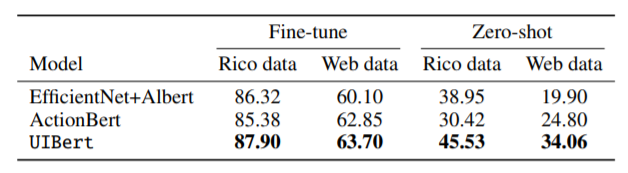
上图为所有下游任务和零次学习的结果,可发现UIBert 在所有情况下都优于两个基线0.85%-9.26%,特别是在零次任务上有很大的优势。
下游任务共分为:
- 相似UI检索,给定一个带有目标成分的目标UI作为查询,以及一个带有一组候选成分的UI,目标是选择与指定成分在功能上最接近的候选成分。
- 基于参考表述的成分检索,输入一个参考表述和一个UI图像,这个任务的目标是从屏幕上检测到的一组UI组件中检索出表述所指的成分。
- 图像-结构数据同步预测,输入结构数据和UI图像,输出其是否对齐。
- APP类型分类,预测APP类型(如音乐,金融等)
- 图标分类,识别图标类型(如菜单,搜索等)
总之:
- 我们提出了UIBert的五个新的预训练任务,利用图像-文本的对应关系,从未标记的数据中学习上下文的UI嵌入。
- 我们在五个类别的九个下游任务中对UIBert进行了评估,包括零次评估。UIBert在所有任务中的表现都优于强大的基线。定性评估也证明了其有效性。
- 我们发布了从Rico延伸出来的两个新数据集,用于两个任务:类似的UI成分检索和参考表述成分检索。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢