
近年来,深度学习的研究热潮持续高涨,各类深度学习框架层出不穷,如TensorFlow、PyTorch、Caffe、MXNet、PaddlePaddle、MindSpore、MegEngine等。在这些框架中用户量最大的是TensorFlow和PyTorch,其中TensorFlow的特点是生态丰富、功能完备,在工业界广泛应用;PyTorch的特点是用户友好、便捷易用,深受科研人员的喜爱。在这个背景下,一流科技创始人袁进辉博士和我们一起探讨了重新设计分布式深度学习框架的必要性。

图1:主流框架特点
1 大模型的趋势
通过对近几年CV、NLP和Speech等领域模型的统计分析,我们发现模型在计算量和参数数量两个维度上均表现出几百倍的增长,并且在最近一年里超大规模的中文预训练语言模型陆续发布,包括OpenAI发布的“GPT-3”、 阿里巴巴发布的270 亿参数量的“PLUG”、华为云发布的千亿级参数的“盘古”以及智源人工智慧研究院发布的万亿参数的“悟道2.0 ”。
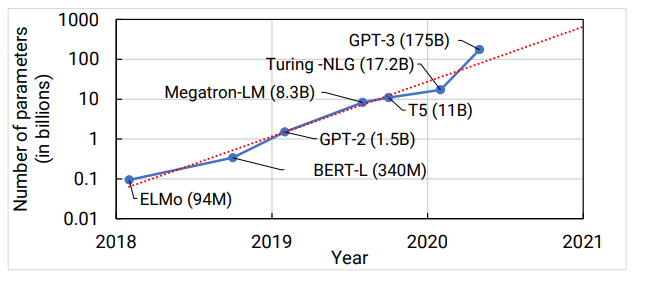
图2:模型参数数量增长趋势
这些大模型在众多自然语言处理任务上出众的表现,使人们相信大模型是未来的发展趋势。但与之带来的挑战是训练超大模型所需的算力和存储在单机上已经无法得到解决,同时意味着训练大模型一定是一个分布式问题,那么如何解决上千块 GPU的分布式训练问题是这个分布式问题的关键所在。
2 分布式训练并行技术
NVIDIA 不久前发表了一篇关于分布式训练的重量级论文《 Efficient Large-Scale Language Model Training on GPU Clusters》,在文章中介绍了分布式训练超大规模模型的三种必须的并行技术:
- 数据并行(Data Parallelism)
数据并行是目前最为广泛使用的并行方式。数据并行是通过将输入数据集分割为更小的批量,并将这些小批量数据集分配到不同的设备中使用,同时每台设备拥有一份完整的模型,通过聚合梯度信息从而使得每台设备均能得到一致的权重参数。
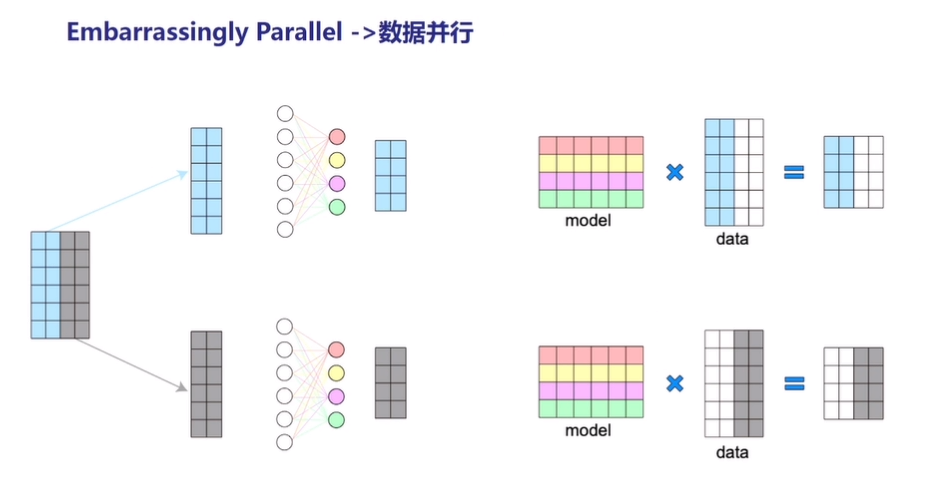
图3:数据并行
- 模型并行(Tensor Model Parallelism)
模型并行是对某一层的模型 Tensor 切分,从而将大的模型 Tensor 分成多个相对较小的 Tensor 进行并行计算。
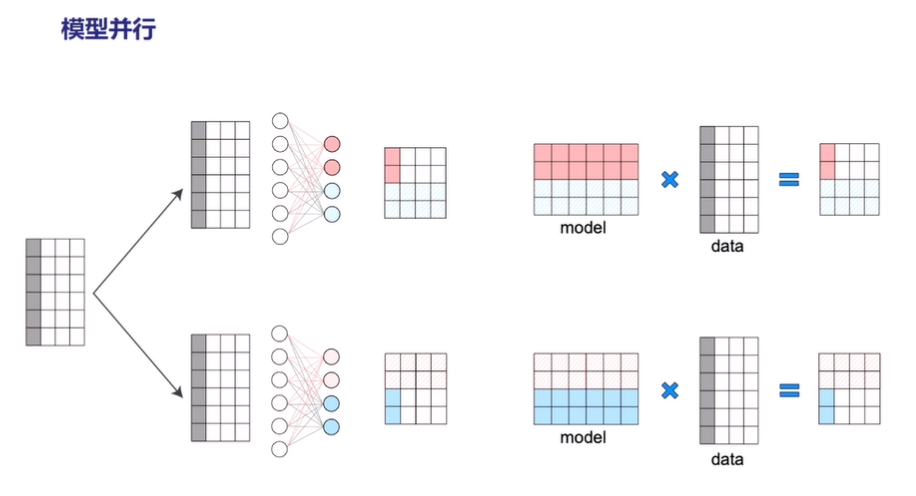
图4:模型并行
- 流水并行(Pipeline Model Parallelism)
流水并行是将整个网络分段(stage),不同段在不同的设备上,前后阶段流水分批工作,通过一种接力的方式并行。
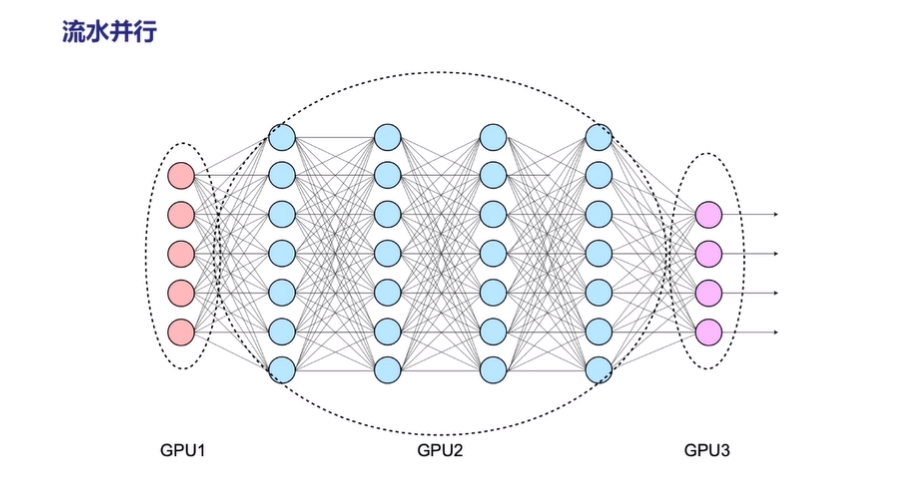
图5:流水并行
下图是NVIDIA训练GPT的网络设计,网络被分割成了 64 个 stage ,每个 stage 跑在 6台 DGX-A100 上。其中 6 台机器之间进行数据并行,每台机器内部的 8 张卡之间做模型并行,整个集群的 3072 张 A100 按照机器拓扑被划分成了 [6 x 8 x 64] 的矩阵,同时使用了数据并行、模型并行、流水并行三种并行技术进行训练。
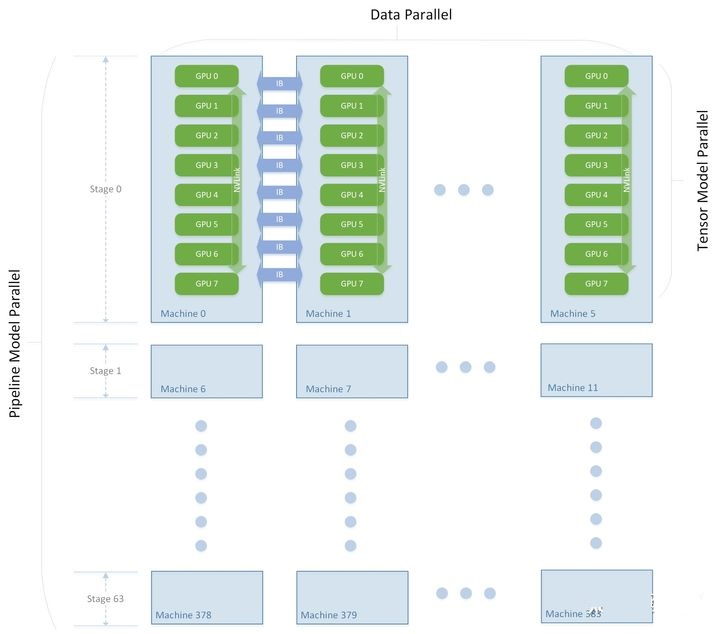
图6:NVIDIA训练GPT的并行技术方案
3 现有框架的局限
目前各大深度学习框架在数据并行方面均实现了非常好的效果,但在模型并行上仍然处于早期阶段。以PyTorch为例,(1)PyTorch 需要人工排线和精细控制流水来实现流水并行;(2)PyTorch 需要开发人员在 kernel 中手写通信原语操作,需要开发人员推导所有的通信位置,才能很好地实现模型并行。以上方面均对开发人员提出了很高的技术要求,从而很难方便易用地实现分布式并行训练。
此外,在运行期阶段,现有深度学习框架的设计也存在不足之处,主要表现在三个方面的局限性:(1)资源约束缺失:在运行期之前缺乏对资源的分析和预先的规划;(2)“数据搬运是二等公民”的思想:在实现计算图的过程通常只考虑计算部分,而忽略了数据搬运部分;(3)中心化调度:目前在TensorFlow等框架中仍然使用的是中心化调度的机制,这种机制会存在单点性能瓶颈问题。
4 OneFlow的技术突破
4.1 运行时 Actor 机制
OneFlow通过运行时Actor机制实现去中心化调度。在整个由Actor构成的静态图中,没有一个中心的调度节点,每个 Actor 当前是否可以执行都仅与自己的状态、空闲 Register数量以及收到的消息有关。所以使用 Actor 做流水并行,本身就不需要自己定制复杂的调度逻辑。同时Actor机制天然支持流水线,Actor 通过内部的状态机和产出的Register个数以及上下游的Register消息机制解决了流控问题。
此外,现有框架在编译期的关注焦点是数据计算,认为数据搬运是背后隐式发生的,因此在静态分析计算图时略过计算和搬运的重叠编排。而OneFlow在计算图中显式表达了数据搬运,而且在静态分析时同等对待数据搬运和数据计算,以最大化重叠搬运和计算。在最终的执行图中,数据搬运操作也是一个个Actor,OneFlow的设计是所有的功能都在一张由Actor组成的静态执行图里实现了,因此OneFlow这样的设计不仅简洁、优雅,并且非常高效。
4.2 SBP机制
SBP( Split、Broadcast、PartiaSum)是OneFlow独创的概念,全称为SbpParallel。它表示一种逻辑上的Tensor与物理上的多个Tensor的映射关系。具体来说:
- Split表示物理上的Tensor是逻辑上的Tensor按照某一维度切分后得到的,如果把多个物理上的Tensor按照Split的维度进行拼接,就能还原出逻辑上的Tensor;
- Broadcast表示物理上的Tensor是和逻辑上的Tensor完全相同的;
- PartialSum表示物理上的Tensor虽然和逻辑上的Tensor形状一致,但是物理上的Tensor里的值是逻辑Tensor里对应位置的一部分,如果把物理上的多个Tensor按照对应位置相加,即可还原出逻辑上的Tensor。
SbpSignature 是一个 SbpParallel 的集合,在 OneFlow 的设计里是 Op 的属性,它描绘了一个逻辑上的 Op 被映射成各个设备上的多个物理上的 Op 后,这些物理上的 Op 是如何看待他们输入输出 Tensor 在逻辑上和物理上的映射关系的。
一个 Op 会有多个合法的 SbpSignature,一个最简单的合法 signature 就是输入输出都是 Broadcast,这表示了这个 Op 需要整个逻辑上的 Tensor 数据。当用户构建的逻辑上的计算图确定以后,OneFlow 在 Compiler 生成分布式的物理上的执行图时,会考虑每个 Op 的 Placement 和该 Op 允许的合法 SbpSignature 列表,在其中选择一个传输开销最小的 SbpSignature 作为本次训练的 SbpSignature,用于指导 Compiler 生成最高效的执行图。
基于SBP+Placement的机制,使得用户定义计算图中的Op、Tensor以任意的方式分布在各个机器和各个设备上。因此,无论是数据并行、模型并行还是流水并行,都只是一个特定Placement下的特定SbpSignature的组合而已。从而使得用户可以方便地配置或由框架实现自动处理。
5 性能对比
- 在流水线并行方面,OneFlow不使用DALI技术和TensorFlow、PyTorch使用DALI技术进行对比,OneFlow效果更好。
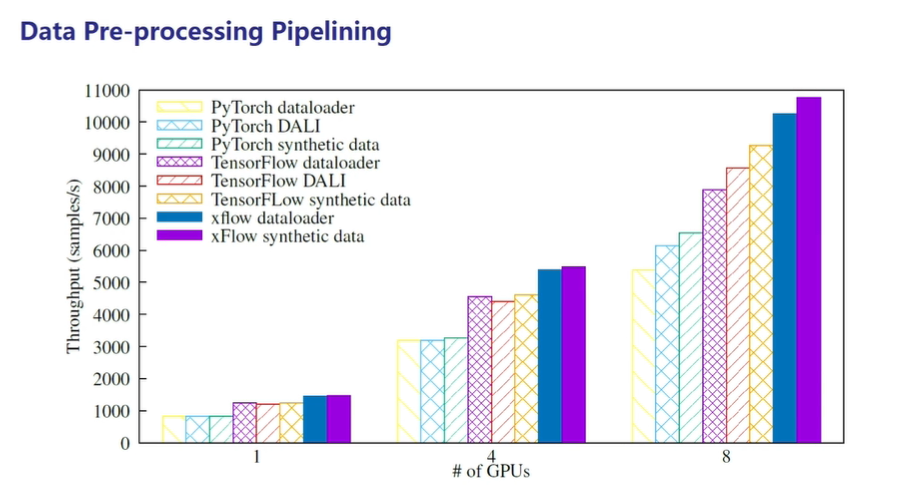
图7:数据预处理性能对比
- 下图中的评测选择了ResNet-50 v1.5和BERT-Base两个经典主流的深度学习模型,其中以NGC开头的框架表示该框架是从NVIDIA GPU Cloud仓库中获取的,经过了英伟达的深度优化,在图中可以看出OneFlow的性能更好。
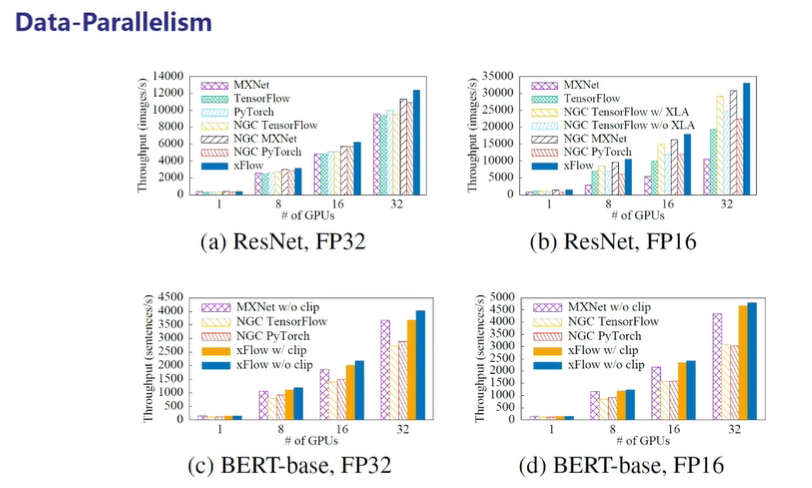
图8:在ResNet-50 v1.5和BERT-Base经典模型上的数据并行性能对比
- 下图比较了 oneflow_face 和 deepinsight 两个仓库在 InsightFace 深度学习模型训练任务上的性能,结果表明OneFlow在 InsightFace 模型上的性能以及分布式环境下的横向扩展能力优于其他框架。
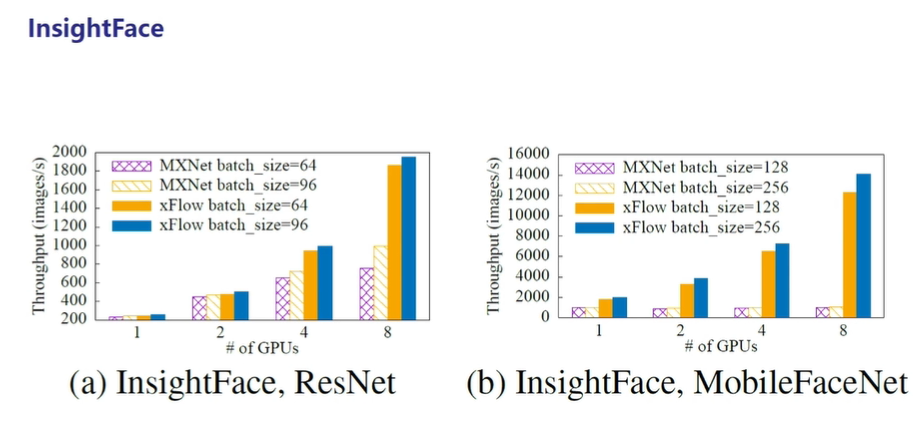
图9:在InsightFace上的性能对比
- 下图展示了OneFlow和Nvidia专为大规模广告推荐场景定制研发的HugeCTR相比较,结果显示OneFlow的延迟更低、更节省显存。
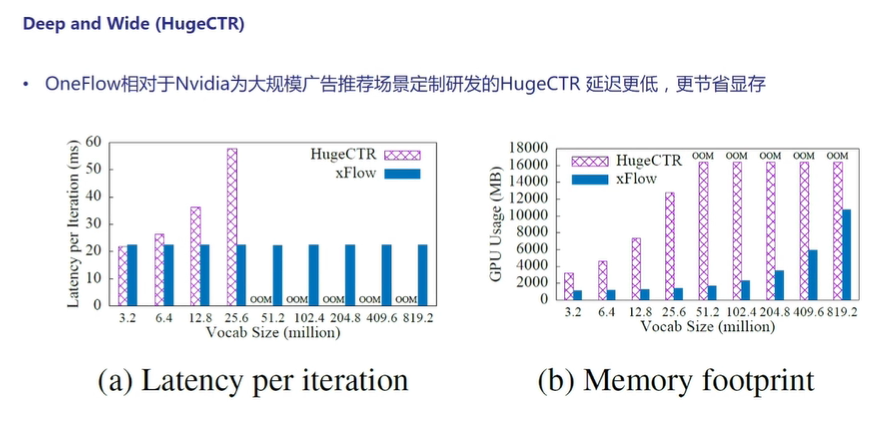
图10:与HugeCTR的性能对比
- 下图展示了OneFlow和微软专为大规模预训练模型定制研发的DeepSpeed相比较,结果显示OneFlow的吞吐量更高、更节省显存。
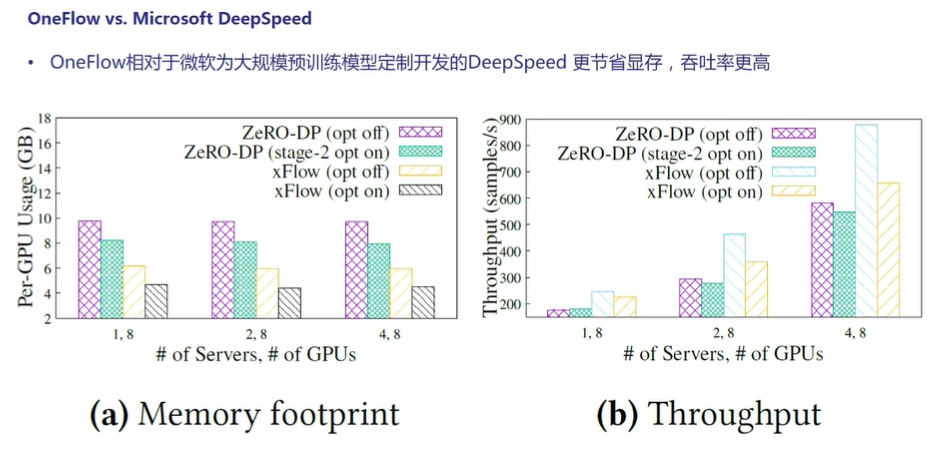
图11:与DeepSpeed的性能对比
- 下图是OneFlow 与经过 NVIDIA 的深度优化的 Megatron 的对比,除了在用户接口和框架设计上OneFlow更简洁、更易用之外,OneFlow在已有的测试规模上性能也领先 Megatron。
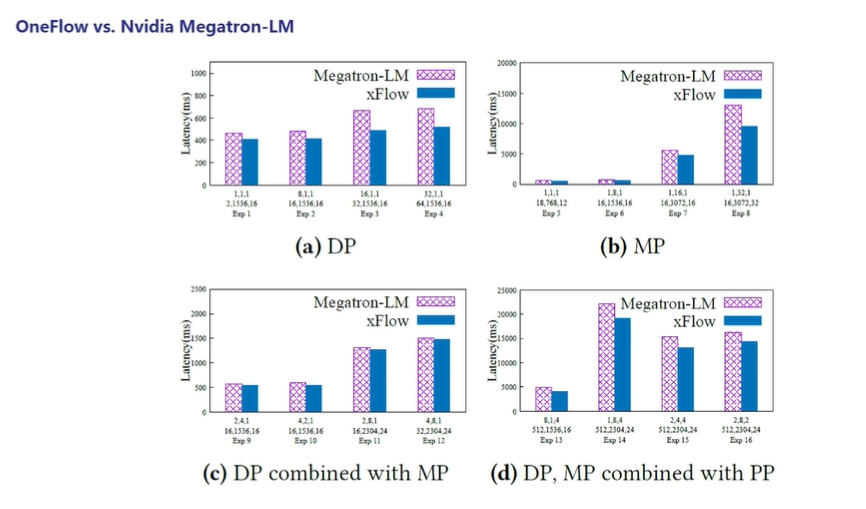
图12:与Megatron的性能对比
6 总结
相较于其他深度学习框架,OneFlow框架在分布式训练领域拥有独特的设计和视角,实现了分布式训练过程中的极致性能和易用体验。同时OneFlow 作为一款新型国产深度学习开源框架,目前仍在快速迭代和完善之中。我们也欢迎大家参与到 OneFlow 的开源项目中,共同打造出一款完美的产品。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢