
【论文标题】Pre-train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing
【作者团队】Pengfei Liu, Weizhe Yuan, Jinlan Fu, Zhengbao Jiang, Hiroaki Hayashi, Graham Neubig
【发表时间】2021/07/28
【机 构】CMU
【论文链接】https://arxiv.org/pdf/2107.13586v1.pdf
【推荐理由】基于prompt方法的预训练范式综述
本文调查并组织了自然语言处理中的一个新范式的研究工作,我们称之为 "基于prompt的学习"。与传统的监督学习不同的是,传统的监督学习是训练一个模型来接受输入x并预测输出y的P(y|x),而基于prompt的学习是基于语言模型,直接对文本的概率进行建模。为了使用这些模型来执行预测任务,原始输入x被使用prompt修改成一个文本字符串prompt x',其中有一些未填充的槽,然后语言模型被用来概率性地填充未填充的信息,得到最终的字符串x,从中可以得出最终的输出y。这个框架是强大而有吸引力的,原因有很多:它允许语言模型在大量的原始文本上进行预训练,通过定义一个新的prompt函数,该模型能够进行几轮甚至零轮的学习,以适应只有少数或没有标记数据的新场景。在本文中,我们介绍了这种有前途的范式的基本原理,描述了一套统一的可以涵盖各种现有的工作的数学符号,并沿着几个维度组织现有的工作,例如选择预训练的模型、prompt和调整策略。
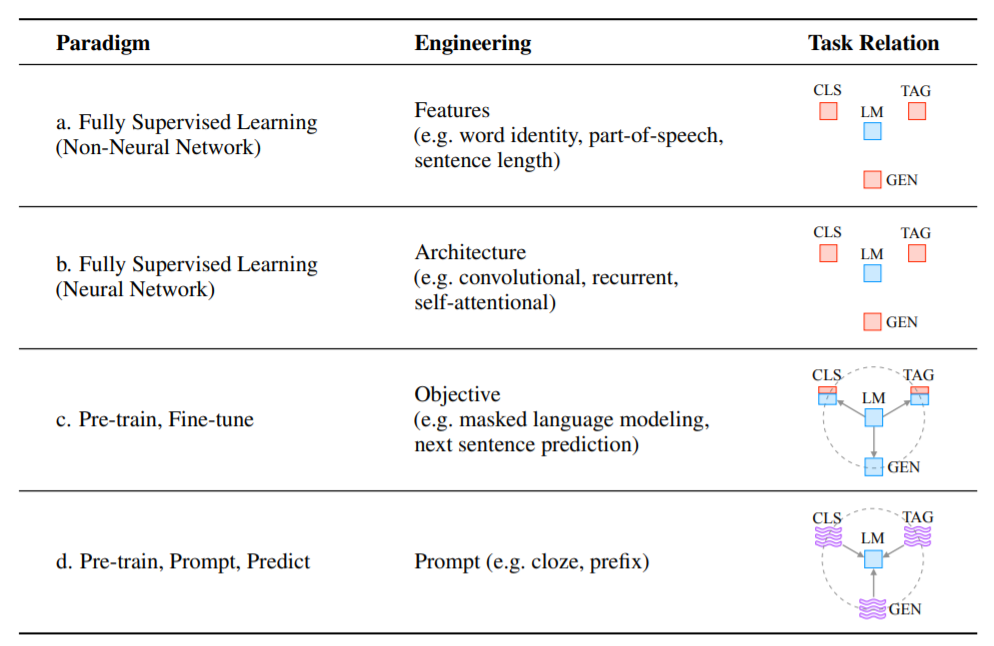
上图展示了NLP中的四种范式。“engineering”一栏代表了建立强大系统所需的工程类型。 “Task relation”一栏,显示了语言模型和其他NLP任务之间的关系,如CLS指代分类,TAG指代标注,GEN指代生成。蓝色图标为无监督学习,红色图标为监督式学习,蓝红色图标为与非监督学习结合的监督学习,紫色波浪图标为语义prompt。虚线表明,不同的任务可以通过共享预训练模型的参数进行连接。"语言模型→任务 "表示将预训练目标适应于下游任务,而 "任务→语言模型 "表示将下游任务适应于LM 。
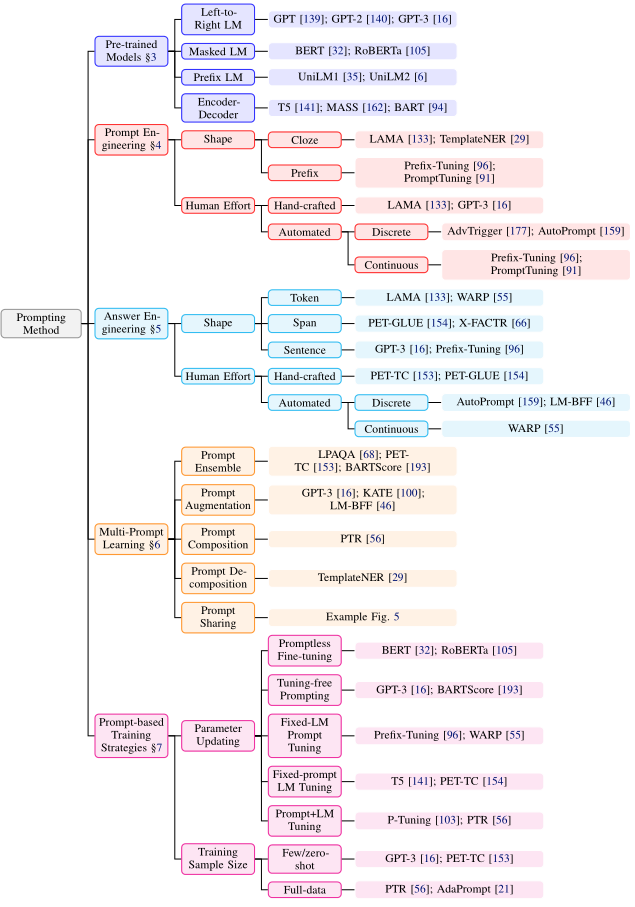
上图展示了prompt方法的逻辑图。主要分为:
- 预训练模型的选择:有各种各样的预训练LM可以用来计算P(x;θ),其中的关键是从解释它们在prompt方法中的效用。
- prompt工程。鉴于prompt指定了任务,选择一个合适的prompt不仅对准确性有很大影响,而且对模型首先执行的任务也有很大影响。
- 答案工程。根据任务的不同,我们可能要以不同的方式设计答案空间。
- 多prompt学习。到目前为止,我们讨论的提示工程方法主要集中在为一个输入构建一个单一的prompt。然而大量的研究表明,使用多个prompt可以进一步提高提示方法的功效。
- 基于prompt的训练策略。由上可以清楚地知道如何获得适当的prompt和相应的答案,本节总结了不同的策略并详细介绍了它们的相对优势。
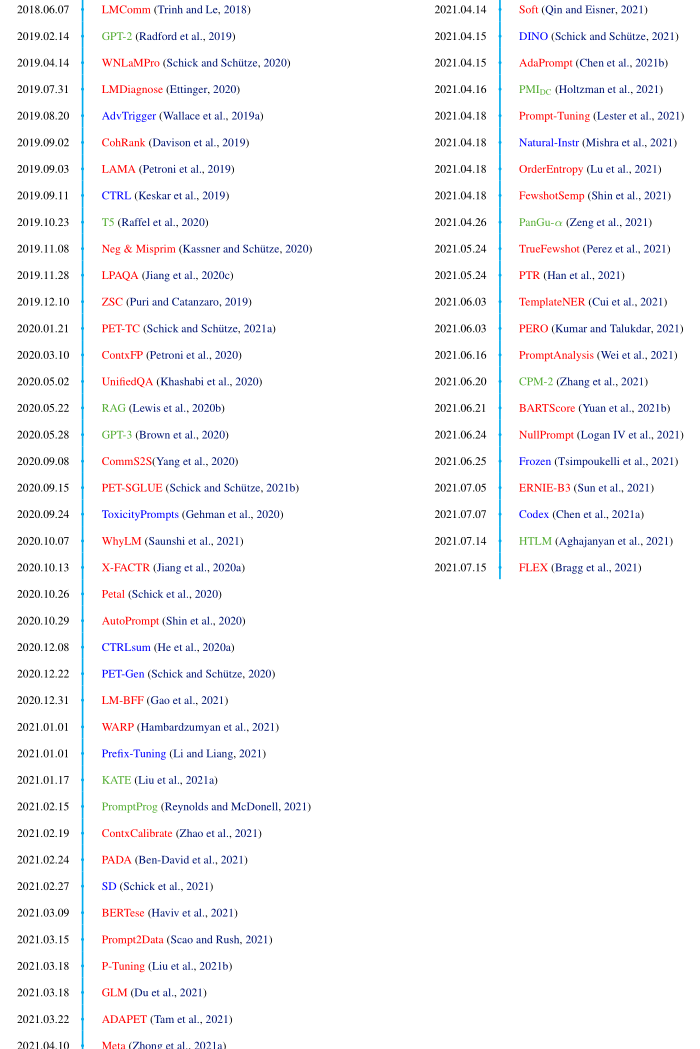
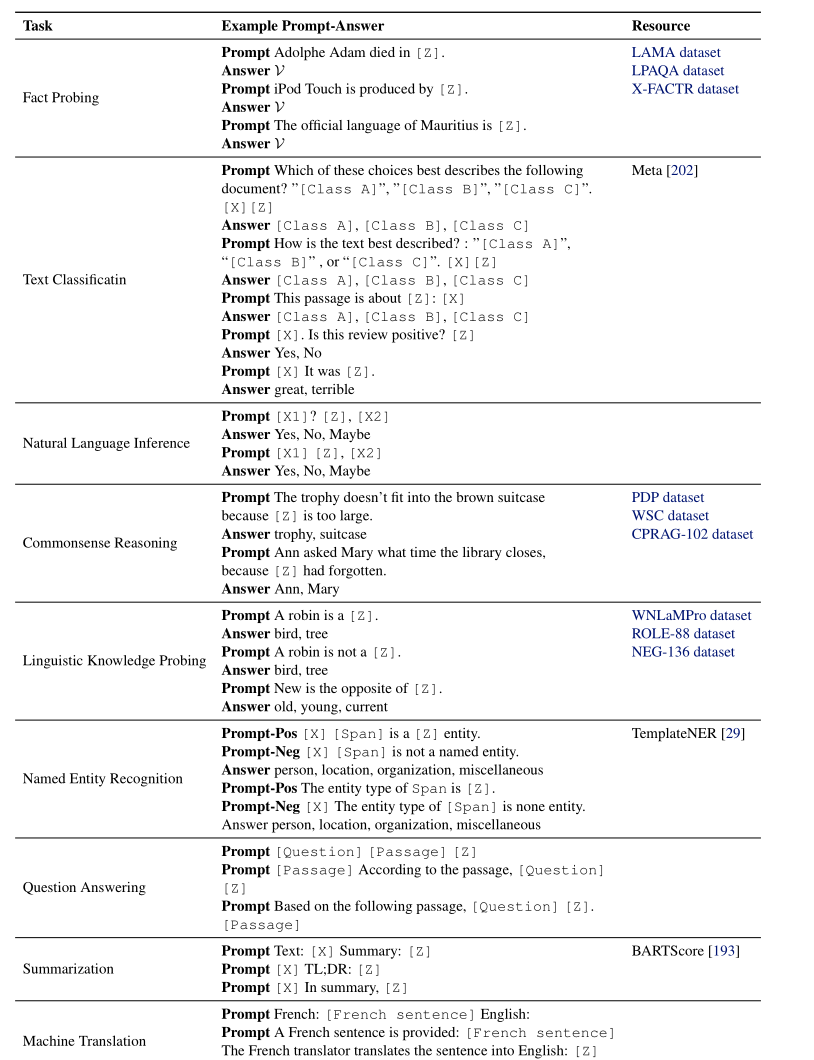
上图展示了截止到2021.7.15,prompt方法发展的时间线,以及prompt方法在各个下游任务中对应的prompt和answer。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢