
【论文标题】Curriculum learning for language modeling
【作者团队】 Daniel Campos
【发表时间】2021/08/04
【机 构】UIUC
【论文链接】https://arxiv.org/pdf/2108.02170v1.pdf
【代码链接】https://github.com/spacemanidol/CurriculumLearningForLanguageModels
【推荐理由】关于课程学习和预训练的一个反面案例
像ELMo和BERT这样的语言模型作为各种下游任务的语言理解组件,提供了强大的自然语言表征。课程学习是一种采用结构化训练体系的方法,它在计算机视觉和机器翻译中被利用来提高模型训练速度和模型性能。虽然语言模型已被证明对自然语言处理界具有变革意义,但这些模型已被证明是昂贵的、能量密集的和具有挑战性的训练。在这项工作中,我们探索了课程学习对语言模型预训练的影响,使用了各种语言学动机的课程,并评估了GLUE基准的迁移性能。尽管有各种各样的训练方法和实验,我们并没有发现令人信服的证据表明课程学习方法可以改善语言模型训练。

上图展示了课程学习CBC(competence based curriculum )算法。语料库X是一个样本S的集合,其中每个样本si是一个词的序列,按难度排序使用一个启发式的方法,如句子长度或单句的稀有性,被分配一个难度。一个模型被分配一个初始能力λ0和一个能力增量λ increment,一个模型的能力分数代表了该模型在训练过程中的进展程度。在每个训练步骤中,模型从低于其当前能力λt的数据中取样,更新其权重,并增加其能力λt。
本文探索了样本难度的8个代用指标:无课程、随机、样本长度、单字样本概率、大字样本概率、三字样本概率、语篇多样性(POS)和样本依赖解析复杂性(DEP)。
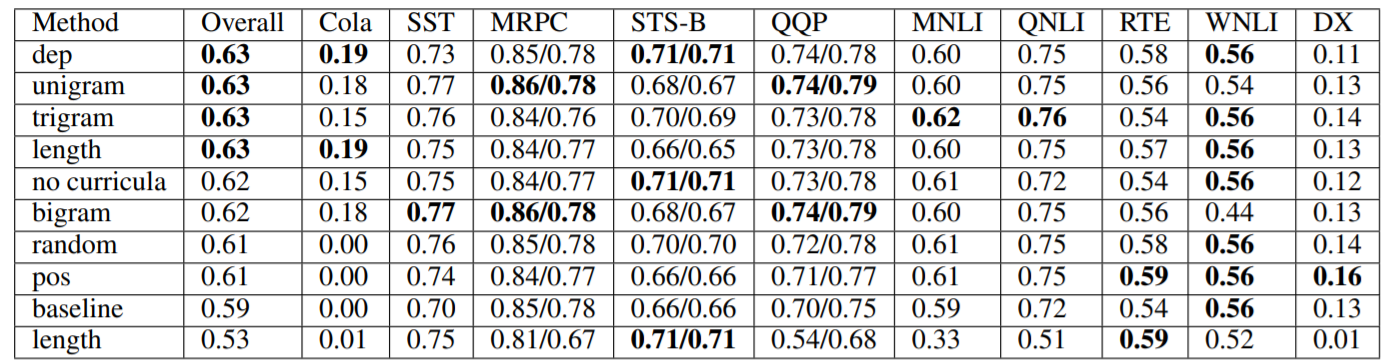
上图展示了在wikitext-2(小)上的结果。我们没有发现强有力的证据表明课程的结构很重要,因为非课程(λ0=1)的表现比其他4种课程和基线的表现更好。也许最令人惊讶的是,尽管训练制度中没有正式的结构,但以总体glue分数来衡量,随机的表现优于基线。在观察单个任务的变异性时,我们发现只有CoLA、STS-B和SST在性能上有广泛的变异性。我们认为这是因为这些任务规模较小,在语言上更具挑战性。

上图展示了在wikitext-3(大)上的结果。我们发现在wikitext-2中发现的趋势不成立,因为最高性能是由基线模型实现的。我们还注意到,系统性能的排序在不同的数据集上并不成立,而且随着预训练数据集的增加,模型之间的差异性也在下降。与较小的语料库类似,我们发现ColA的灵敏度最高,并发现SST和STS-B的变异性变得更加柔和。
结论:
- 在我们的工作中,我们没有发现有力的证据表明使用课程学习能够改善语言模型的预训练。我们的基于CBC的训练机制无法学习到训练语料库的良好表征,但是他们的表征可以很好地迁移到下游的NLP任务中。我们发现,在预训练语料库较小的情况下,CBC方法可以胜过随机抽样,但随着语料库规模的扩大,这种优势就会消失。此外,我们没有发现任何证据表明任何类型的启发式难度对CBC来说都是比较合适的。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢