
【标题】Adapting to Reward Progressivity via Spectral Reinforcement Learning
【作者】Michael Dann, John Thangarajah
【论文链接】https://arxiv.org/pdf/2104.14138.pdf
【发表日期】2021.4.29
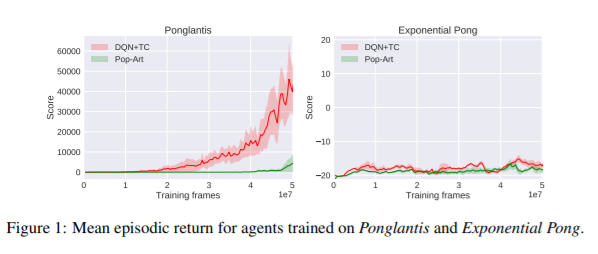
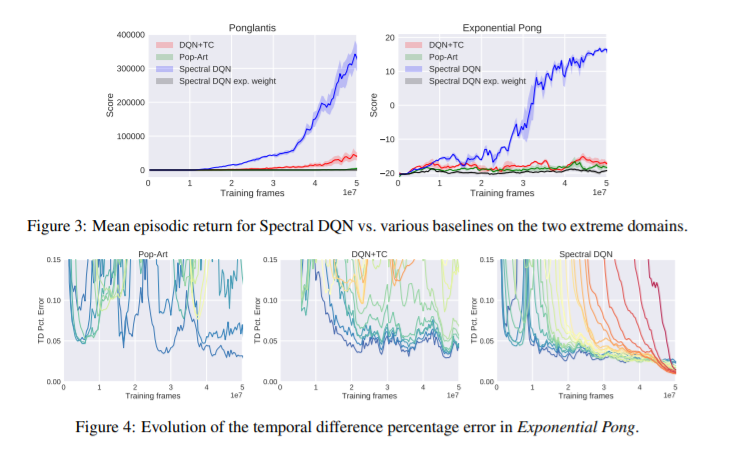
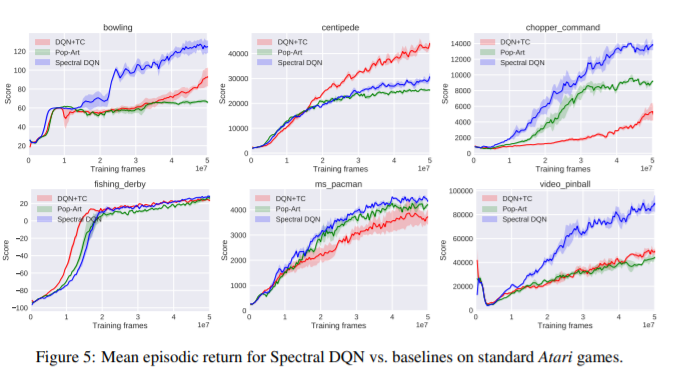
【推荐理由】本文考虑了具有渐进奖励的强化学习任务;即奖励往往会随着时间的推移而增加的任务。其假设对于基于价值的深度强化学习代理来说,这个属性可能是有问题的,特别是如果代理必须首先在任务中相对无奖励的区域取得成功,才能到达更多有奖励的区域。为了解决这个问题,本文提出了 Spectral DQN,它将奖励分解为频率,使得高频仅在发现大奖励时激活。并且其允许平衡训练损失,以便在大小奖励区域之间提供更均匀的权重。在具有极端奖励渐进性的两个领域中,基于价值的标准方法存在显着问题,而Spectral DQN 能够取得更进一步的进展。此外,当在一组不明显支持该方法的标准 Atari 游戏上进行评估时,Spectral DQN 仍然具有较强竞争力:虽然它在一场游戏中的表现低于基准之一,但在三场游戏中却轻松地超过了基准。这些结果表明该方法并没有对其目标问题过度拟合,并且表明 了Spectral DQN 可能具有解决奖励渐进性之外的优势。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢