
这些神经网络使用的流程,基本可以概括为:1) 固定网络架构,初始化网络参数;2) 训练阶段:在训练集上优化网络参数;3) 推理阶段:固定网络架构与参数,输入测试样本进行前向传播,得到预测结果。
这种范式导致训练完成后,在测试阶段,对所有的输入样本,均采用相同的网络架构与参数进行推理。这在一定程度上限制了模型的表征能力、推理效率和可解释性。
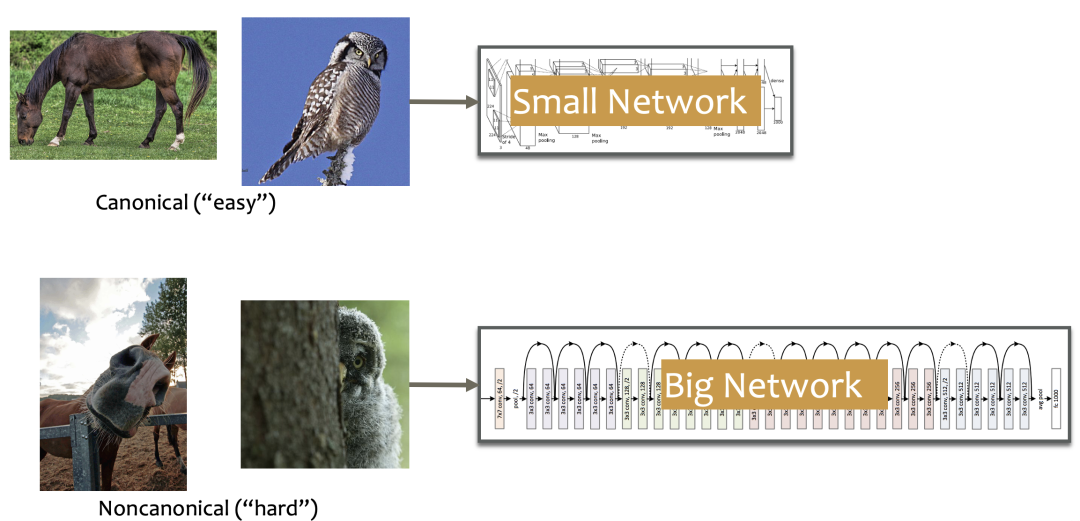
一个非常明显的例子,如下图所示,对于常见的「马」或「猫头鹰」的图片,也许只需要一个小的网络便可以正确识别;然而对于「非经典」的「马」或「猫头鹰」的图片,则需要训练一个大的网络才能正确识别。
再例如,如下图所示,对一张包含「猫」的图片进行识别,我们可以看到,提高分辨率确实可以提高准确率,但同时也伴随着计算量的极速提升。人们自然期望是否可以在不严重影响准确率的情况下,降低输入样本的分辨率,从而来节省计算量。

将这一系列要求「自适应推理」的问题总结起来,便是所谓「动态神经网络」的研究范畴。
与静态网络不同的是,动态网络的本质在于,在处理不同测试样本时,能够动态地调节自身的结构/参数,从而在推理效率、表达能力、自适应性等方面展现出卓越的优势。
内容目录
一、神经网络,如何动起来?
1)样本自适应动态网络
动态结构
动态参数
2)空间自适应动态网络
像素级
区域级
分辨率级
3)时间自适应动态网络
二、六大开放问题
1)结构设计;
2)更多样任务下的适用性;
3)实际效率与理论的差距;
4)鲁棒性;
5)可解释性;
6)动态网络理论。
详细内容,请关注「智源社区」公众号:https://mp.weixin.qq.com/s/0nmfBKSmVyg1akCsIzH_UA

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢