
论文标题:RaftMLP: Do MLP-based Models Dream of Winning Over Computer Vision?
论文链接:https://arxiv.org/abs/2108.04384
代码链接:https://github.com/okojoalg/raft-mlp
作者单位:立教大学
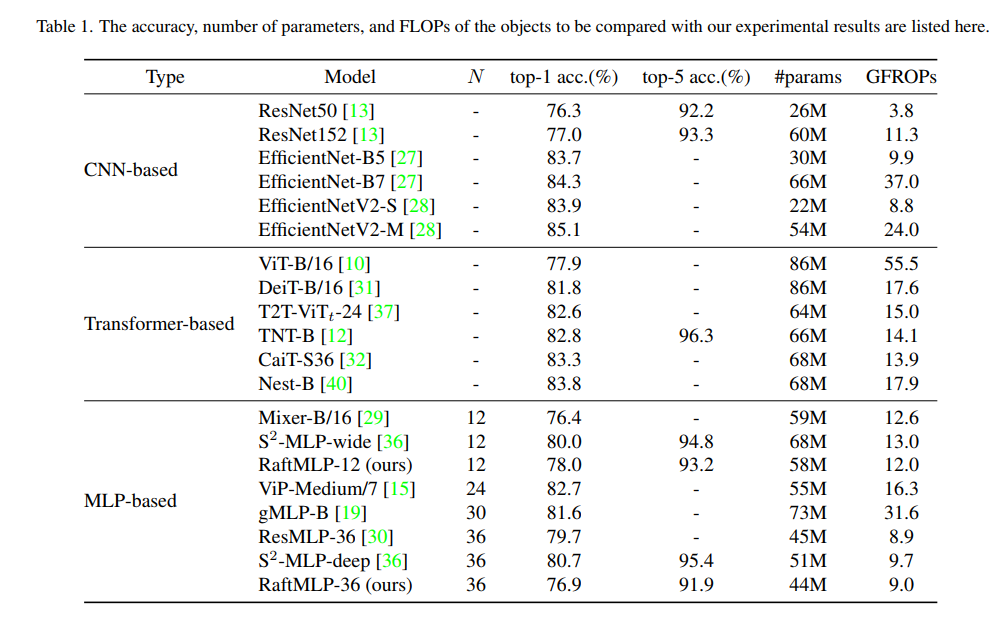
本文提出两种新方法,能够提高 MLP-Mixer 的准确性,同时降低其参数和计算复杂度,该工作表明,基于 MLP 的模型有可能通过采用归纳偏置来取代 CNN,代码刚刚开源!
在过去的十年里,CNN 在计算机视觉领域占据着至高无上的地位,但最近,Transformer 正在崛起。然而,自注意力的quadratic计算成本已经成为一个严重的实践问题。在这种情况下,已经有很多关于没有 CNN 和 self-attention 的架构的研究。特别是,MLP-Mixer 是一个使用 MLP 设计的简单想法,并且达到了与 Vision Transformer 相当的准确度。然而,这种架构中唯一的归纳偏差是token的嵌入。因此,仍然有可能在架构本身中构建非卷积归纳偏置,我们使用两个简单的想法建立了归纳偏置。一种方法是垂直和水平划分token混合块。另一种方法是使某些token混合通道之间的空间相关性更加密集。通过这种方法,我们能够提高 MLP-Mixer 的准确性,同时降低其参数和计算复杂度。与其他基于 MLP 的模型相比,所提出的名为 RaftMLP 的模型在计算复杂度、参数数量和实际内存使用量之间取得了良好的平衡。此外,我们的工作表明,基于 MLP 的模型有可能通过采用归纳偏置来取代 CNN。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢