
论文标题:One Million Scenes for Autonomous Driving: ONCE Dataset
论文链接:https://arxiv.org/abs/2106.11037
代码链接:https://github.com/PointsCoder/ONCE_Benchmark
作者单位:香港中文大学 & 华为诺亚方舟实验室
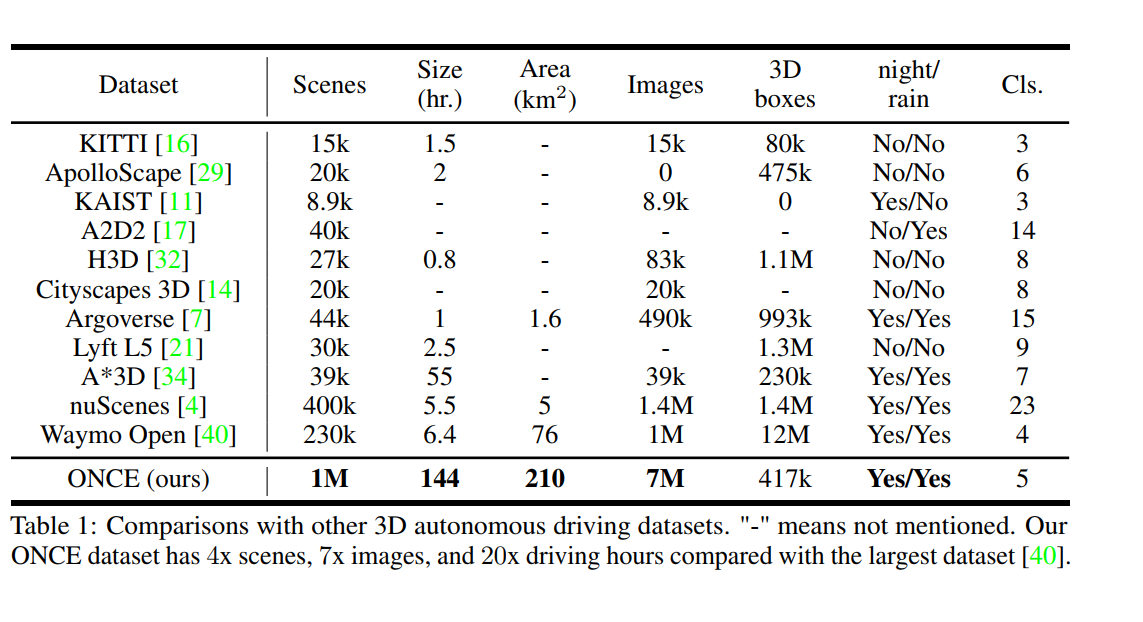
ONCE 数据集包含100万帧3D点云场景,每个3D场景有7个相机拍摄覆盖360度视角的图片,共计700万张图片。其中挑选了1.5万帧点云,标注了5类3D检测框(Car/Bus/Truck/Pedestrian/Cyclist)。研究者既可以使用1.5万标注数据训练自己的模型,也可以探索如何利用100万无标签数据进一步提升模型的鲁棒性和性能,数据集和代码现已开源!
当前自动驾驶中的感知模型因极大地依赖大量带注释的数据来覆盖unseen的情况并解决长尾问题而臭名昭著。另一方面,从未标记的大规模采集数据中学习和增量自训练强大的识别模型受到越来越多的关注,并可能成为下一代行业级强大而鲁棒的自动驾驶感知模型的解决方案。然而,研究界普遍存在那些基本的真实世界场景数据的数据不足,这阻碍了未来对 3D 感知的全/半/自监督方法的探索。在本文中,我们介绍了用于自动驾驶场景中 3D 对象检测的 ONCE(一百万个场景)数据集。 ONCE 数据集由 100 万个 LiDAR 场景和 700 万个相应的相机图像组成。数据选自 144 个驾驶小时,比可用的最大 3D 自动驾驶数据集(例如 nuScenes 和 Waymo)长 20 倍,并在一系列不同的区域、时期和天气条件下收集。为了促进未来对利用未标记数据进行 3D 检测的研究,我们还提供了一个基准,在该基准中我们在 ONCE 数据集上重现和评估各种自监督和半监督方法。我们对这些方法进行了广泛的分析,并就其与所用数据规模相关的性能提供了有价值的观察。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢