标题:清华|FlipDA: Effective and Robust Data Augmentation for Few-Shot Learning(FlipDA:有效且稳健的数据增强小样本学习)
https://github.com/zhouj8553/FlipDA
http://arxiv-download.xixiaoyao.cn/pdf/2108.06332.pdf
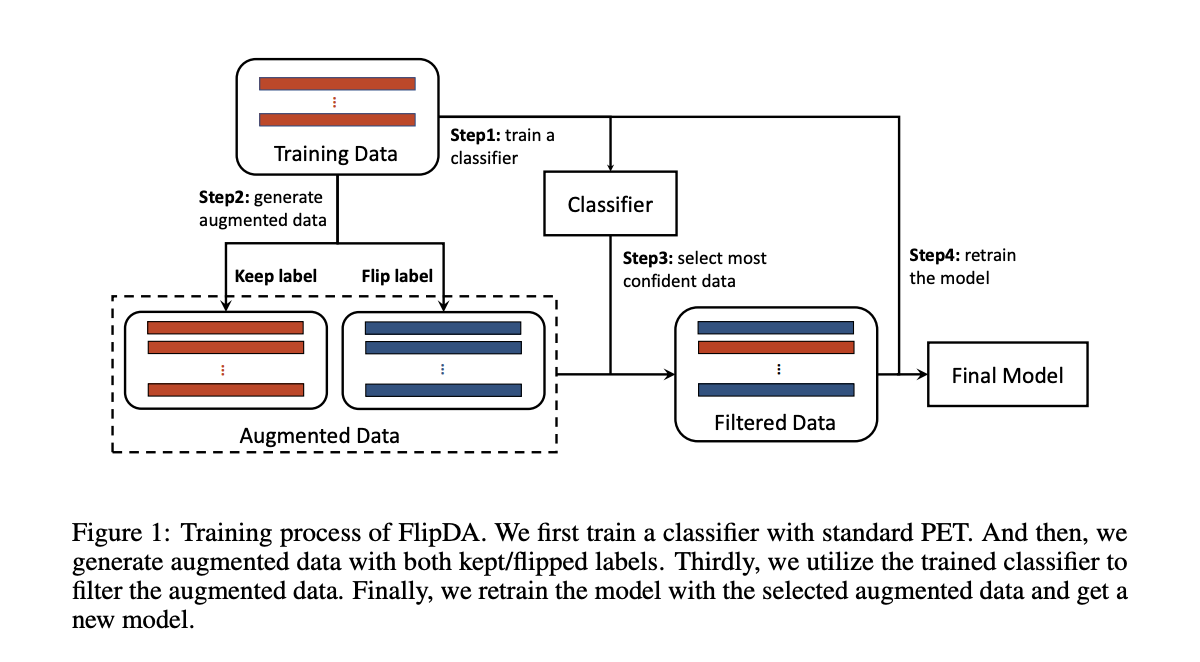
内容中包含的图片若涉及版权问题,请及时与我们联系删除

https://github.com/zhouj8553/FlipDA
http://arxiv-download.xixiaoyao.cn/pdf/2108.06332.pdf
内容中包含的图片若涉及版权问题,请及时与我们联系删除
沙发等你来抢

评论
沙发等你来抢