
论文标题:TVT: Transferable Vision Transformer for Unsupervised Domain Adaptation
论文链接:https://arxiv.org/abs/2108.05988
作者单位:德克萨斯大学阿灵顿分校 & 快手科技
本文首次全面研究了ViT在各种领域自适应任务上的可迁移性,并提出一个可迁移视觉Transformer:TVT,表现SOTA!性能优于SHOT、ALDA等网络。
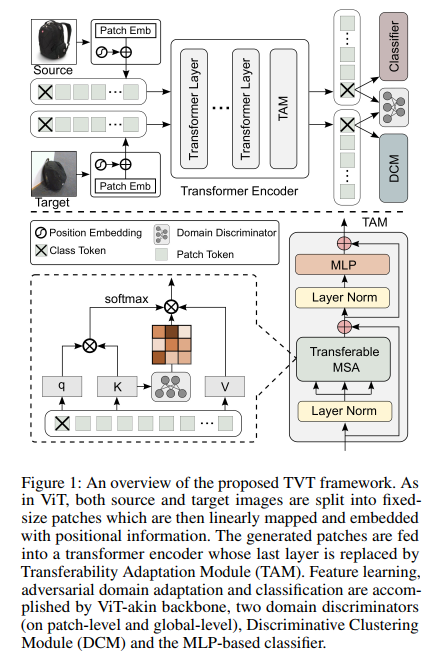
无监督域自适应 (UDA) 旨在将从标记的源域中学到的知识迁移到未标记的目标域。以前的工作主要建立在卷积神经网络 (CNN) 上来学习域不变表示。随着最近将 Vision Transformer (ViT) 应用于视觉任务的指数增长,ViT 在适应跨域知识方面的能力在文献中仍未得到探索。为了填补这一空白,本文首先全面研究了 ViT 在各种领域适应任务上的可迁移性。令人惊讶的是,与基于 CNN 的同类产品相比,ViT 表现出优异的可迁移性,而且性能可以通过结合对抗性适应进一步提高。尽管如此,直接使用基于 CNN 的自适应策略未能利用 ViT 的内在优点(例如,注意力机制和顺序图像表示),这在知识迁移中起着重要作用。为了解决这个问题,我们提出了一个统一的框架,即可迁移视觉Transformer(TVT),以充分利用 ViT 的可掐木偶性进行领域适应。具体来说,我们精心设计了一个新颖而有效的单元,我们将其称为可转移性适应模块 (TAM)。通过将学习到的可迁移性注入注意力块,TAM 迫使 ViT 专注于可迁移和判别特征。此外,我们利用判别聚类来增强在对抗域对齐过程中被破坏的特征多样性和分离。为了验证其多功能性,我们在四个基准上对 TVT 进行了广泛的研究,实验结果表明,与现有最先进的 UDA 方法相比,TVT 取得了显著的改进。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢