
【论文标题】Modeling Protein Using Large-scale Pretrain Language Model
【作者团队】Yijia Xiao, Jiezhong Qiu, Ziang Li, Chang-Yu Hsieh, Jie Tang
【发表时间】2021/08/17
【机 构】清华、智源、腾讯
【论文链接】https://arxiv.org/abs/2108.07435v1
【代码链接】https://github.com/THUDM/ProteinLM
【推荐理由】悟道·文溯的30亿参数蛋白预训练模型
蛋白质几乎与所有生命过程都有联系,因此分析蛋白质序列的生物结构和特性对探索生命以及疾病检测和药物发现至关重要。传统的蛋白质分析方法往往是劳动密集型和耗时的,而深度学习模型的出现使得在大数据中建立数据模式成为可能。跨学科研究人员已经开始利用深度学习方法对大型生物数据集进行建模,例如,使用长短期记忆和卷积神经网络进行蛋白质序列分类。经过数百万年的进化,进化信息被编码在蛋白质序列中。受自然语言和蛋白质序列之间的相似性的启发,我们使用大规模的语言模型对进化规模的蛋白质序列进行建模,将蛋白质生物学信息进行编码表示。在标识符级和序列级任务中都观察到了明显的改进,表明我们的大规模模型能够准确地从进化规模的单个序列的预训练中捕捉到进化信息。
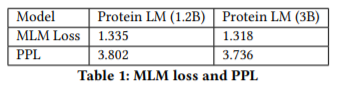
上图显示了预训练部分的loss以及perplexity。
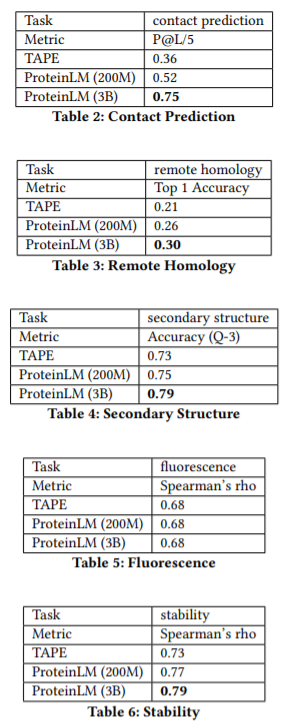
上图显示了30亿参数的模型在5个标准下游任务上的表现以及和基线模型的对比。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢