【标题】Offline Preference-Based Apprenticeship Learning
【作者】Daniel Shin, Daniel S. Brown
【发表日期】2021.7.22
【论文链接】https://arxiv.org/pdf/2107.09251.pdf
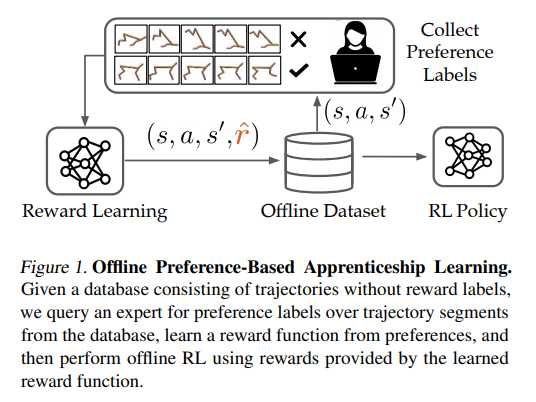
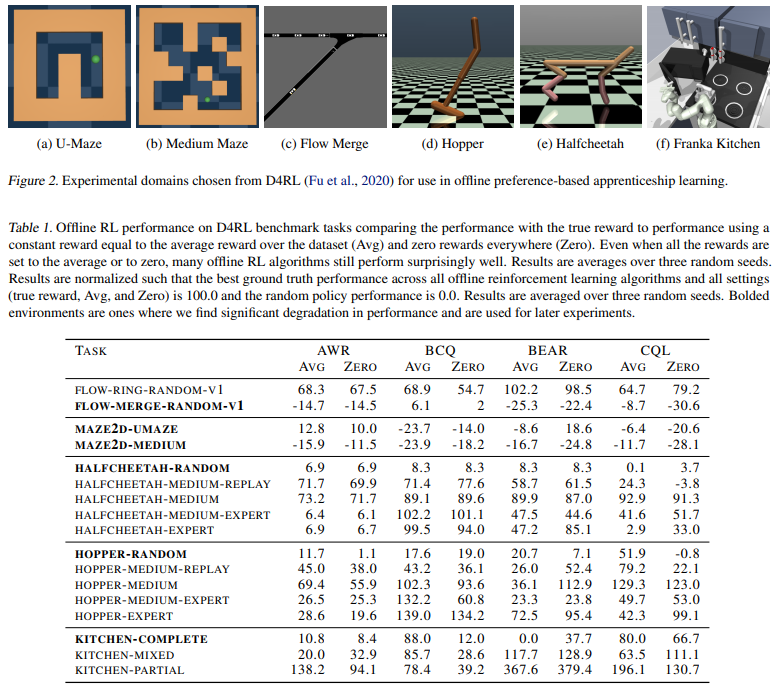
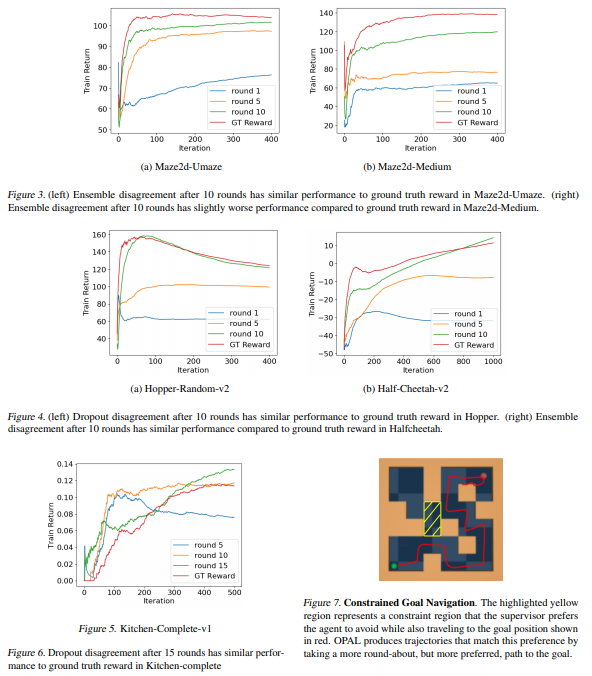
【推荐理由】本文研究了如何使用先前(可能是随机的)经验的离线数据集来解决自主系统在努力向人类学习、适应和协作时面临的两个挑战:(1)识别人类的意图和(2)安全地优化自治系统的行为以实现这种推断的意图。首先,本文使用离线数据集通过基于池的主动偏好学习有效地推断人类的奖励函数。其次,鉴于这个学习奖励函数,本文执行离线强化学习根据推断的人类意图优化策略。至关重要的是,提出的方法不需要实际物理部署或用于奖励学习或策略优化步骤的准确模拟器,从而实现安全高效的学徒学习。在现有离线 RL 基准的子集上识别和评估了该方法,这些基准非常适合离线奖励学习,并评估了这些基准的扩展,这些基准允许更多开放式行为。实验表明离线离线基于偏好的奖励学习和离线强化学习能够实现高效、高性能的策略,同时只需要少量的偏好查询。视频可在 https://sites.google.com/view/offline-prefs 获得。
内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢