
【论文标题】Program Synthesis with Large Language Models
【作者团队】Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, Charles Sutton
【发表时间】2021/08/16
【机 构】谷歌
【论文链接】https://arxiv.org/abs/2108.07732v1
【推荐理由】自然语言与编程语言之间的交互
本文探讨了当前用于通用编程语言程序合成的大型语言模型的极限。我们在MBPP和MathQA-Python这两个新的基准上对参数在244M和137B之间的,在小样本和微调状态下进行的模型的集合进行了评估。我们的基准是为了衡量这些模型从自然语言描述中合成短的Python程序的能力
Mostly Basic Programming Problems (MBPP)数据集包含974个编程任务,旨在让入门级的程序员能够解决。MathQA-Python数据集是MathQA基准的Python版本,包含23914个问题,评估模型从更复杂文本中合成代码的能力。在这两个数据集上,我们发现合成性能与模型大小呈对数线性关系。我们最大的模型,即使没有在代码数据集上进行微调,也能通过精心设计的提示,用小样本学习来合成MBPP中59.6%的问题的解决方案。在大多数模型中,对数据集的一部分进行微调,可以提高约10个百分点的性能。在MathQA-Python数据集上,最大的微调模型达到了83.8%的准确性。
更进一步,我们研究了模型参与关于代码的对话的能力,结合人类的反馈来改进其解决方案。我们发现,与模型的初始预测相比,人类的自然语言反馈使错误率减半。此外,我们还进行了错误分析,以阐明这些模型的不足之处以及哪些类型的程序最难生成。最后,我们通过微调这些模型以预测程序执行的结果来探索这些模型的语义基础。我们发现,即使是我们最好的模型一般也不能预测给定的特定输入的程序的输出。
本文的主要贡献:
- 我们引入两个数据集来测试Python代码的合成。
- 在这两个数据集上,我们表明,一个大的语言模型在从提示到Python程序的几次小样本合成中表现得出奇地好。
- 除了单步程序合成之外,我们还研究了该模型参与代码对话的能力,并根据人类的自然语言反馈来改善其性能。
- 我们探索我们的模型的语义基础,研究这些模型在多大程度上可以执行给定的特定输入代码。
- 我们分析了性能对各种因素的敏感性,包括模型大小、提示中的例子数量、提示中的例子身份、采样技术等

上图显示了人类-模型合作实验的 "流程 "概述。人类给出所需程序的描述,然后通过对话引导模型走向正确的解决方案。
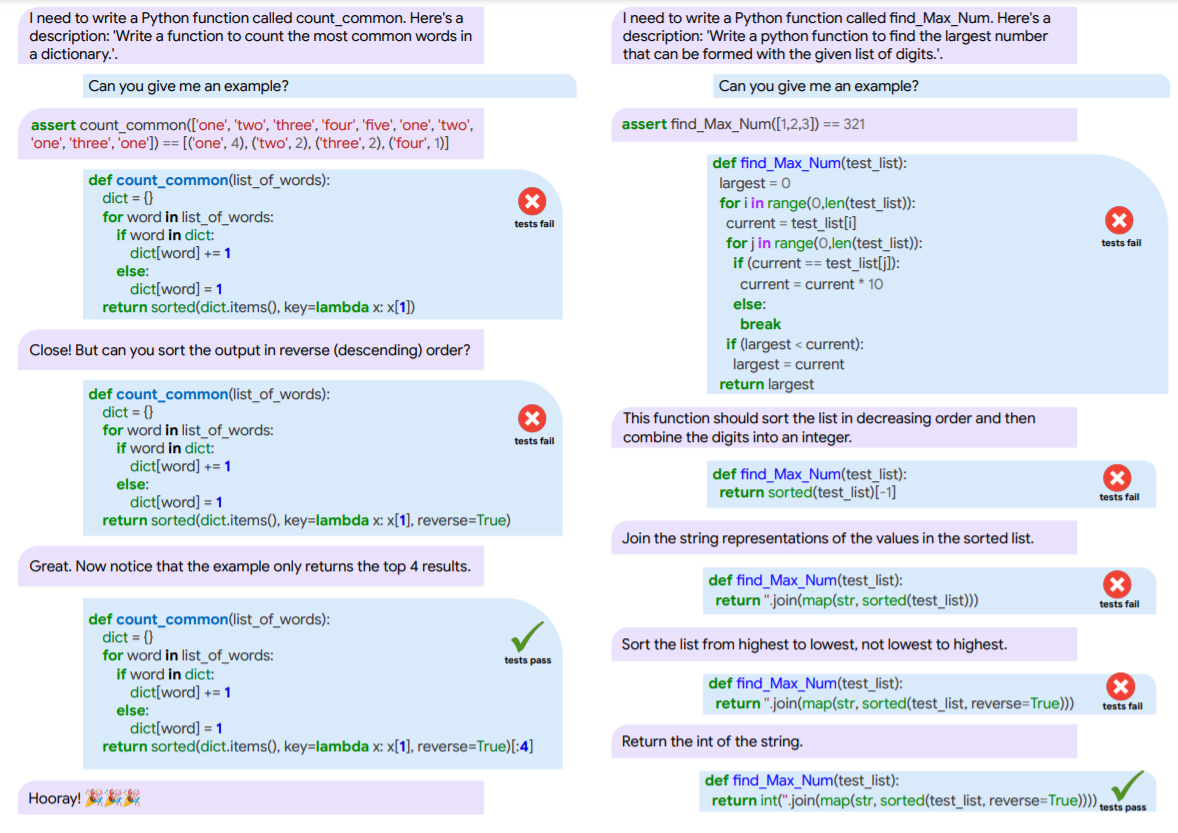
两个人类与模型互动的例子。用户文本为紫色,模型文本为蓝色。左图:一个不甚明确的问题,用户能够根据例子的输入指出修正。右图:一个更长更复杂的例子,其中模型根据反馈做出了小的调整。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢