标题:谷歌|Do Vision Transformers See Like Convolutional Neural Networks? (视觉变换器跟卷积神经网络观察是同样的原理吗?)
推荐理由:阐述了视觉变换器网络机制的核心原理
作者:谷歌大脑团队Maithra Raghu、 Alexey Dosovitskiy
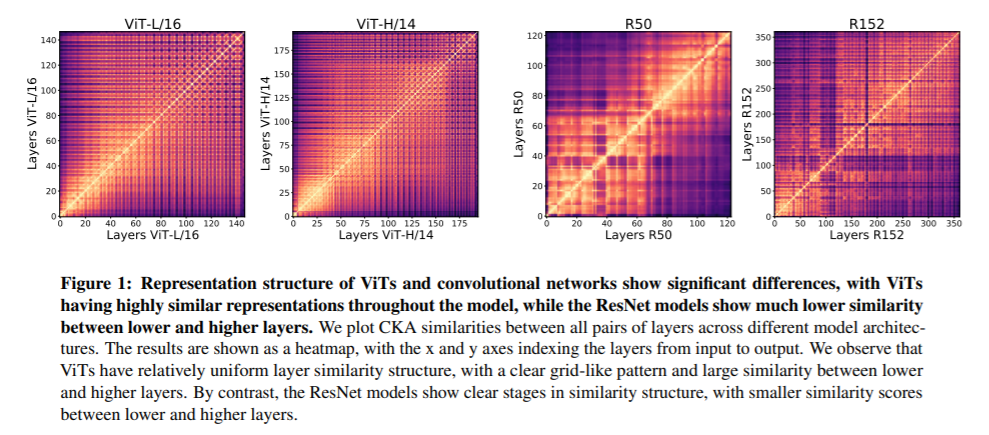
简介:迄今为止,卷积神经网络已成为视觉数据的事实上的模型。近期工作已经表明视觉变换器模型 (ViT) 可以在图像分类任务中使用。这就提出了一个核心问题:Vision Transformers 如何解决这些任务?它们是像卷积网络一样工作,还是学习完全不同的视觉表示?分析ViT和 CNN在图像分类基准上的内部表示结构,我们发现两种架构之间的惊人差异,例如 ViT 在所有层上具有更统一的表示。我们探索这些差异是如何产生的,找到自注意力所扮演的关键角色,这使得早期全局信息和ViT残差连接的聚合,它们从低层到高层强烈地传播。我们研究了空间定位的后果,成功证明了ViT保留输入空间信息,不同分类方法的效果显着。最后,我们研究预训练数据集规模对中间特征和迁移学习的影响,并讨论新架构(如 MLP-Mixer)的相关结论。
下载地址:https://arxiv.org/pdf/2108.08810v1.pdf
内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢