
【论文标题】Medical-VLBERT: Medical Visual Language BERT for COVID-19 CT Report Generation With Alternate Learning
【作者团队】Guangyi Liu, Yinghong Liao, Fuyu Wang, Bin Zhang, Lu Zhang, Xiaodan Liang, Xiang Wan, Shaolin Li, Zhen Li, Shuixing Zhang, Shuguang Cui
【通讯作者】崔曙光
【发表时间】2021/08/18
【机 构】港中大深圳、中山大学、暨南大学等
【论文链接】https://arxiv.org/abs/2108.05067v2
【推荐理由】多模态预训练模型在新冠诊断上的临床应用点
医学影像技术,包括计算机断层扫描(CT)或胸部X射线(CXR),主要用于促进COVID-19的诊断。由于人工撰写报告通常过于耗时,因此迫切需要一个更加智能的辅助医疗系统,能够自动并立即生成医疗报告。在这篇文章中,我们建议使用医学视觉语言BERT(Medical-VLBERT)模型来识别COVID-19扫描的异常情况,并根据检测到的病变区域自动生成医疗报告。为了产生更准确的医疗报告,并尽量减少视觉和语言的差异,该模型采用了一种交替的学习策略,包括两个程序,即知识预训练和迁移。更确切地说,知识预训练程序是记忆医学文本中的知识,而迁移程序是通过观察医学图像,将获得的知识用于专业的医疗句子生成。在实践中,为了自动生成COVID-19病例的医疗报告,我们构建了一个数据集,其中包括368个中文医疗结论和1104个胸部CT扫描,这些数据来自中国广州暨南大学第一附属医院和中国珠海中山大学第五附属医院。此外,为了缓解COVID-19训练样本的不足,我们的模型首先在大规模的中国CX-CHR数据集上进行训练,然后迁移到COVID-19 CT数据集上进行进一步微调。实验结果表明,Medical-VLBERT在中国COVID-19 CT数据集和CX-CHR数据集的术语预测和报告生成方面取得了最先进的表现。
本文的主要亮点为:
- 我们提出了用于自动生成医疗报告的Medical-VLBERT。据我们所知,这是第一个可以为COVID-19 CT扫描生成医疗报告的模型。
- 我们在模型训练中采用了迁移学习策略,以缓解现有COVID-19数据的不足。所迁移的知识为医疗报告的生成提供了专业指导。我们的模型在COVID-19 CT数据集的术语预测和报告生成方面都取得了最先进的表现。
- 我们为预训练和迁移程序开发了一种替代的训练策略,以尽量减少医学扫描和诊断文本之间的差异,并最大限度地提高所生成报告的准确性。
- 我们建立了一个COVID-19 CT数据集,该数据集包含1 104张CT扫描和368份由专业放射医师根据《新型冠状病毒肺炎诊治方案》指导下的96名患者的标准化中文医疗报告。我们已经向社会发布了COVID-19 CT数据集。
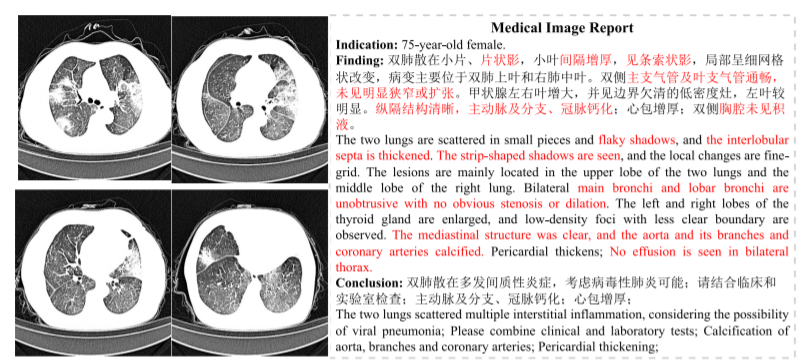
上图显示了COVID-19医疗影像报告的中文例子。研究结果中的医学术语被标记为红色。自动生成医疗报告的智能系统需要准确地使用这些术语,为放射科医生提供一个报告模板,其中包括各个病变的细节,如形状、密度和边界。有了这个模板,放射科医生不仅可以快速定位和分析病变区域,不需要费力的搜索,而且通过简单的内容修改就可以在短时间内生成一份医疗报告。
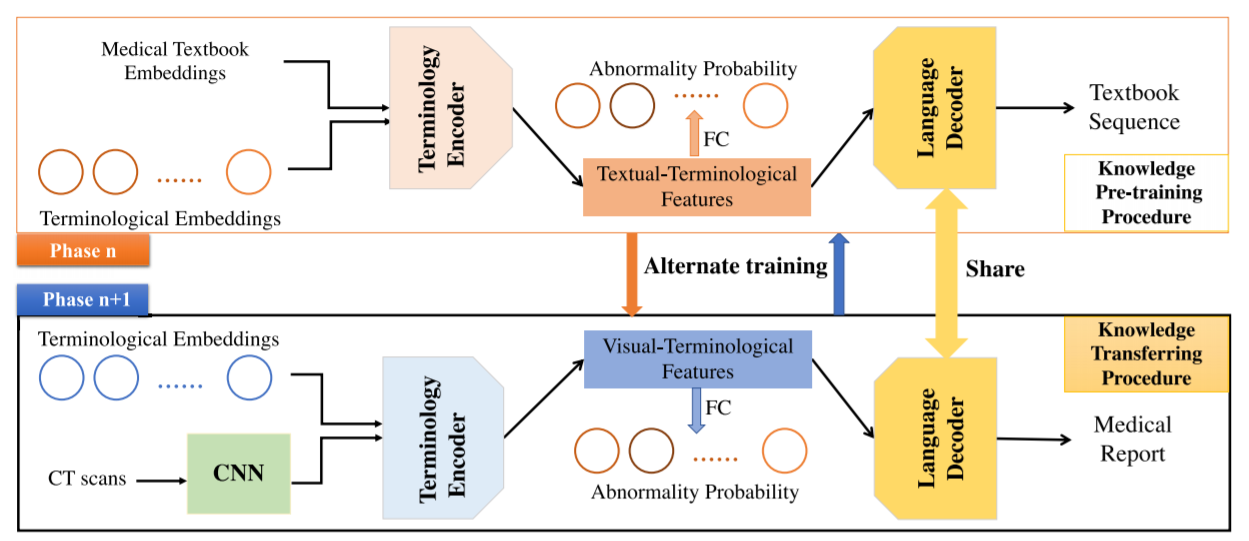
上图展示了Medical-VLBERT概述。输入的图像首先通过一个卷积神经网络(CNN)被编码为空间特征,作为视觉背景。然后设计两个独立的术语编码器,将预定义的术语嵌入与视觉背景和医学教科书嵌入联系起来,从而产生相应的视觉-术语和文本-术语特征。此外,交替的训练策略被利用来减少这两个术语相关特征之间的差异。基于视觉-术语学和文本-术语学特征,一个共享语言解码器被用来生成报告序列和医学教科书序列。

上图为由Medical-VLBERT和DenseNet+GPT-2生成的报告的插图。下划线的句子是对病变的描述,与ground truth中的原始描述相吻合。所选的CT扫描是来自测试数据集。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢