

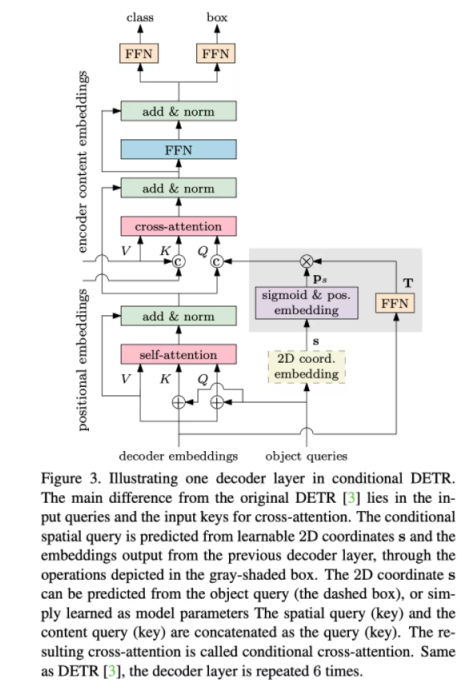
在这篇论文中,针对 DEtection Transformer (DETR) 训练收敛慢的问题(需要训练 500 epoch 才能获得比较好的效果)提出了 conditional cross-attention mechanism,该机制的核心是从 decoder embedding 和 reference point 中学习到一个 conditional spatial query。通过 conditional spatial query 显式地寻找物体的 extremity 区域,从而缩小搜索物体的范围,加速了收敛。结构上只需要对 DETR 的 cross-attention 部分做微小的改动,就能将收敛速度提高 6-10 倍。
论文标题:
Conditional DETR for Fast Training Convergence
论文链接:
https://arxiv.org/pdf/2108.06152.pdf
代码链接:
https://github.com/Atten4Vis/ConditionalDETR
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢