
【论文标题】Pretrained Transformers for Text Ranking: BERT and Beyond
【作者团队】Jimmy Lin, Rodrigo Nogueira, Andrew Yates
【通讯作者】Andrew Yates
【发表时间】2021/08/20
【机 构】滑铁卢大学、马普所
【论文链接】https://arxiv.org/abs/2010.06467v3
【推荐理由】预训练Transformer在文本排名上的应用综述
文本排名的目标是生成一个响应查询而从语料库中检索到的文本的有序列表。尽管文本排名最常见的表述是搜索,但在许多自然语言处理的应用中也可以发现该任务的实例。本调查提供了一个关于使用被称为transformer的神经网络架构进行文本排名的概述,其中BERT是最著名的例子。Transformer和自监督预训练的结合已经在自然语言处理、信息检索和其他领域实现了范式转变。在这份调查报告中,我们提供了一份现有工作的综述以帮助希望更好地了解如何将Transformer应用于文本排名问题的从业人员和希望在这一领域开展工作的研究人员。我们涵盖了广泛的现代技术,分为两个高层次的类别:在多阶段架构中执行重新排序的Transformer模型和直接执行排序的密集检索技术。有两个主题贯穿了我们的调查:处理长文档的技术,超越了NLP中典型的逐句处理,以及解决有效性(即结果质量)和效率(如查询延迟、模型和索引大小)之间权衡的技术。尽管Transformer架构和预训练技术是最近的创新,但它们如何应用于文本排名的许多方面都是相对较好的理解,代表了成熟的技术。然而,仍然有许多开放的研究问题,因此,除了为文本排名的预训练Transformer奠定基础外,本综述还试图预测该领域的发展方向。
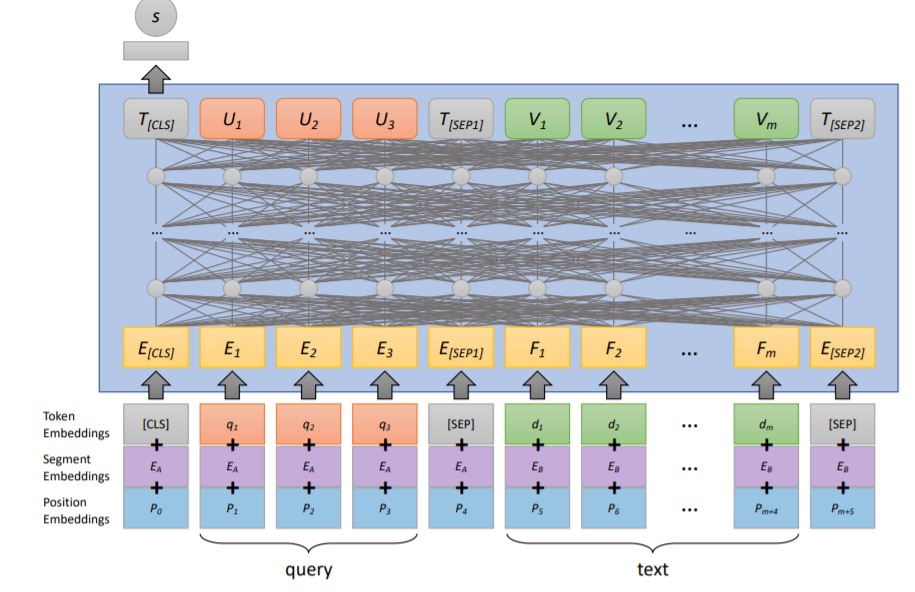
上图展示了一个用于文本排名的模型,monoBERT排名模型。其将BERT适应于相关性分类,将查询和待评分的候选文本(由适当的特殊标记包围)作为输入。输入向量表示包括标记嵌入、段嵌入和位置嵌入的元素相加。BERT模型的输出是每个输入标记的上下文嵌入。[CLS]标记的最终表示被送入一个全连接层,该层产生文本与查询的相关性分数。
除去Transformer以外其他方法包括基于表征的方法,基于交互的方法等。用于排名的Transformer表征与传统基于表征的方法最为相似,只是使用了更强大的基于Transformer的编码器来为查询和语料库中的文本建模。

上图显示了各种模型对MS MARCO语料库中的段落进行预测查询的例子,与来自相关性判断的用户查询进行比较。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢