
论文标题:
Does Knowledge Distillation Really Work?
论文地址:
https://arxiv.org/pdf/2106.05945
随着自然语言处理进入了预训练模型的时代,模型的规模也在极速增长,GPT-3甚至有1750亿参数。如何在资源有限的情况下部署使用这些庞大的模型是一个很大的挑战。
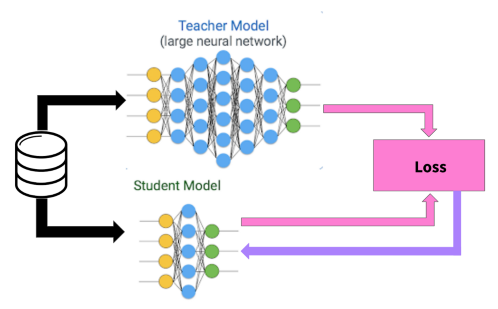
目前知识蒸馏在解决这一问题中的方法中占据了重要的地位。我们可以通过知识蒸馏来学习容易使用的小型学生模型,但是它真的可以起到蒸馏教师模型知识的效果吗?在这篇文章中,作者对这一问题进行了详细的探索与解答,下面我们就来一探究竟。
作者总结了本文的关键发现:
学生模型的泛化性能(generalization)和匹配度(fidelity)的变化趋势并不一致 学生模型的匹配度(fidelity)和蒸馏的校准(calibration)有很大的关联 知识蒸馏过程中的优化是很困难的,这也是导致低匹配度的主要原因 蒸馏优化的复杂度以及蒸馏数据的质量之间存在均衡(trade-off)
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢