【标题】Adaptive Focus for Efficient Video Recognition
【作者】Yulin Wang, Zhaoxi Chen, Haojun Jiang, Shiji Song, Yizeng Han, Gao Huang
【论文链接】https://arxiv.org/pdf/2105.03245.pdf
【发表日期】2021.8.18
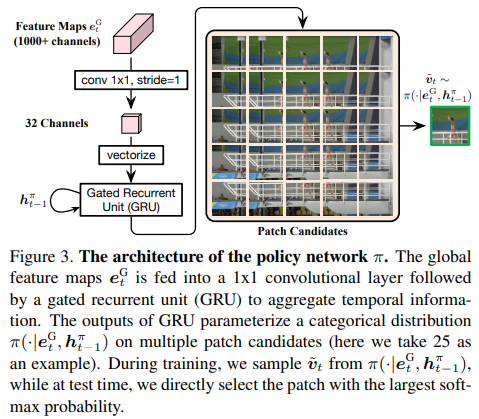
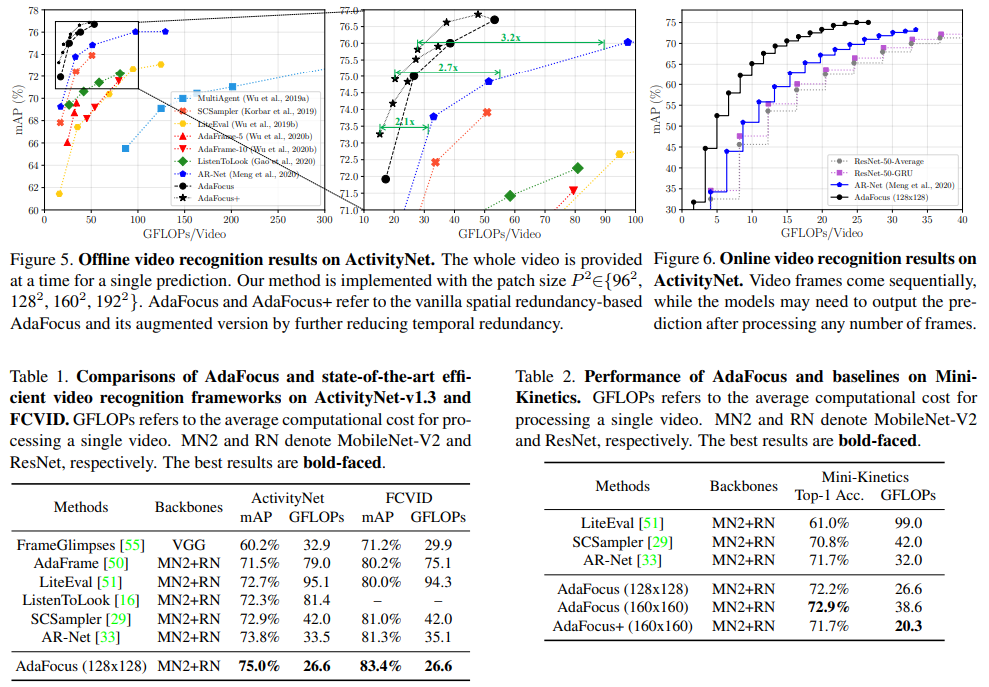
【推荐理由】本文探索了视频识别中的空间冗余,旨在提高计算效率。据观察,视频每一帧中信息量最大的区域通常是一个小的图像块,它在帧间平滑地移动。因此,本文将补丁定位问题建模为一个序列决策任务,并提出了基于强化学习的高效空间自适应视频识别的方法 (AdaFocus)。具体来说,首先采用轻量级 ConvNet 来快速处理完整的视频序列,循环策略网络使用其特征来定位与任务最相关的区域。然后由高容量网络推断选定的补丁以进行最终预测。在离线推理期间,一旦生成了信息补丁序列,就可以并行完成大量计算,并且在现代 GPU 设备上是高效的。此外,本文证明了所提出的方法可以通过进一步考虑时间冗余来轻松扩展,例如,动态跳过价值较低的帧。在五个基准数据集上进行了大量实验,即 ActivityNet、FCVID、Mini-Kinetics、Something-Something V1&V2、证明了该方法比竞争基线更有效。代码可在 https://github.com/blackfeather-wang/AdaFocus 获得。

内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢