
标题:普林斯顿、MIT|提示:在 NLP 任务中使用语言模型的更好方法
作者:普林斯顿高天宇、陈丹奇助理教授
从 BERT开始,在下游应用程序中使用特定任务的头部微调预训练语言模型 (LM) 已成为 NLP 的标准做法。然而,具有 175B 参数的 GPT-3 模型带来了一种将 LM 用于下游任务的新方法:正如标题“语言模型是少镜头学习者”所暗示的那样,GPT-3 可以很好地处理通过利用自然语言提示和任务演示作为上下文,同时不更新底层模型中的参数,可以使用只有几个示例的广泛任务。 GPT-3 庞大的模型规模是其成功的重要因素,而提示和演示的概念也让我们对如何更好地使用语言模型有了新的认识。
那么什么是提示呢?提示是插入到输入示例中的一段文本,因此可以将原始任务表述为(屏蔽的)语言建模问题。例如,假设我们要对电影评论“无理由观看”的情感进行分类,我们可以在句子中附加一个提示“这是”,得到无理由观看。它是____”。很自然地期望语言模型产生“可怕的”而不是“伟大的”的概率更高。这篇文章回顾了大型语言模型中提示的最新进展。
GPT-3 发布后,出现了很多与提示相关的论文,其中很多都讨论了 BERT(BERT-base 有 110M 个参数,比最大的 GPT 小 1000 倍)等中等规模的预训练模型的基于提示的学习。在这篇文章中,将概述最近的基于提示的方法以及我对提示的看法。
为什么使用提示?
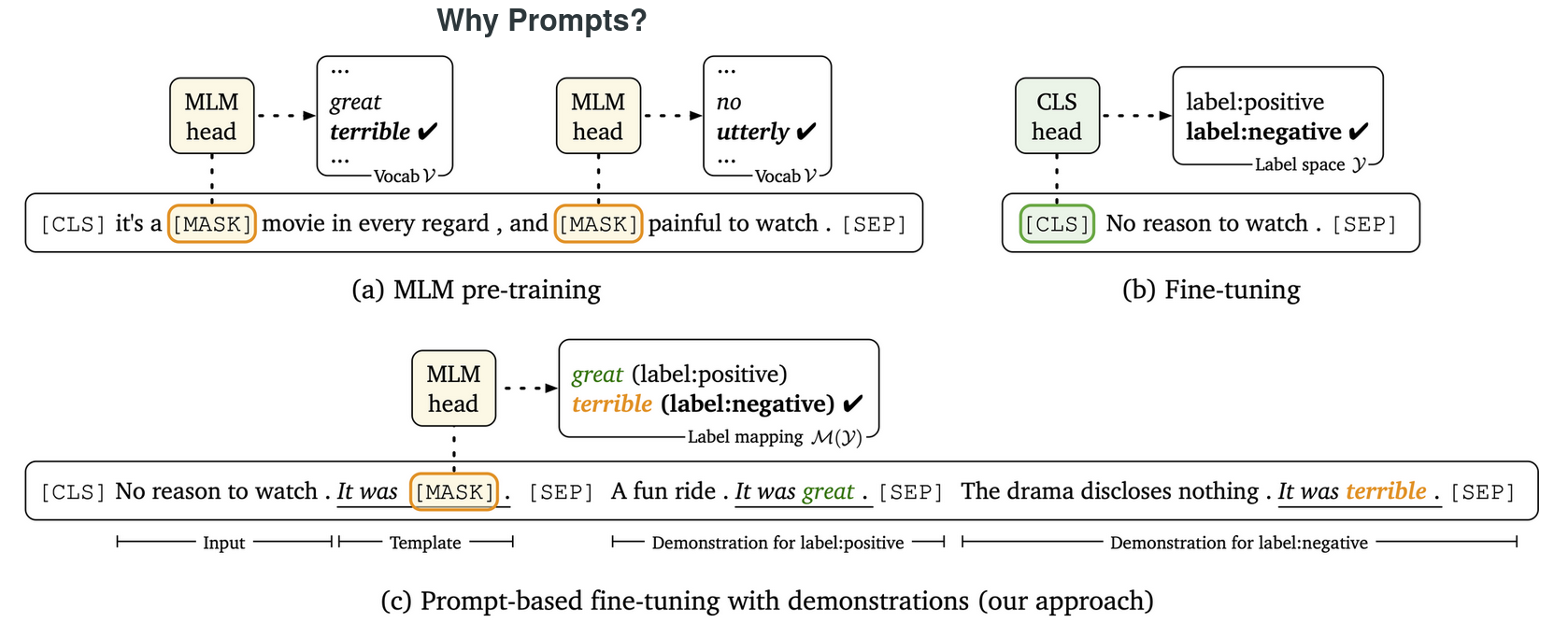
图1
在标准的“预训练和微调”范式中,预训练阶段和下游任务之间的差距可能很大:目标不同,对于下游任务,我们通常需要引入新的参数——对于例如,对于 BERT 大型模型和二元分类任务,它需要一组额外的 1,024 x 2 参数。另一方面,提示使得下游任务可以采用与预训练目标相同的格式,如图1所示,并且不需要新的参数。对于分类任务,我们只需要设计一个模板(“It was”)和预期的文本响应(我们称这些标签词,例如图1中正标签为“great”,负标签为“terrible” )。通过缩小两个阶段之间的差距,在特定任务上部署预先训练的模型变得更加容易,特别是对于少样本的情况——当你只有十几个训练样本来完成一项新任务时,很难精确——有效地调整预先训练的模型和新的特定于任务的参数,但这个过程在提示下要顺畅得多。 Scao 和 Rush表明一个提示可能值 100 个常规数据点,表明提示可以带来样本效率的巨大飞跃。
提示的研究有两种不同的范式,他们有不同的观点:受 PET 论文的启发,基于提示的微调(关键点是我们仍然进一步优化参数) 被认为是通往更好的小语言模型的小样本学习者的途径(小的,数百万而不是数十亿的参数,如 BERT 或 RoBERTa);对于像 175B GPT-3 和 11B T5这样的超大型模型,因为微调它们很困难(这只是猜测,从来没有机会这样做)而且成本很高,而是希望通过不同的提示(离散的或软的,将在后面讨论)来修复它们的参数并应用它们到不同的任务。
离散提示
在预训练模型中使用提示的最早工作可以追溯到 GPT-1/2,作者表明,通过设计适当的提示,LM 可以在任务上实现不错的零样本性能从情感分类到阅读理解。后来,Petroni 等人、戴维森等人、江等人、Talmor探索利用提示从 LM 中挖掘事实或常识知识。在 GPT-3 在固定参数的同时采取提示后,基于提示的方法被进一步引入较小的 LM。它们与 GPT-3 的不同之处在于它们对完整模型进行了微调,并采用双向掩码 LM 而不是单向 LM。最近的几篇论文通过调整目标或以统一形式制定任务,如问答或文本蕴涵来遵循这一方法。 .在所有这些模型中,提示都是自然语言,由词汇表中的离散标记组成。通过对不同变体的全面研究表明,当采取基于提示的微调(而不是冻结所有参数)时,该模型也可以获得比没有提示的标准微调更好的性能(但一个好的提示仍然会有显着的差异),并且只调优部分模型参数——例如,采用最近提出的偏差调整方法——可与小样本设置中的完整模型微调相媲美。
大多数工作都需要手动设计的提示——提示工程非常重要,因为小的扰动会显着影响模型的性能,创建完美的提示需要了解 LM 的内部工作原理和反复试验。
与手动设计的提示相比,还可以生成或优化提示:Guo等人展示了一种适用于提示生成的软Q学习方法; AutoPrompt建议采用基于梯度的搜索(该想法来自 Wallace 等人,旨在搜索通用对抗性触发器以使模型生成特定预测)以找出最佳的提示特定任务。 AutoPrompt 的设置不同,因为它修复了模型:它只是假设所有内容都在预训练模型中编码,我们需要的只是“提示”它;另一个原因是 AutoPrompt 还针对LAMA,这是一项知识探测任务,要求不触及模型参数。以下是用于情感分类的 AutoPrompt 示例。
搜索到的模板显着提高了 LAMA 性能; 他们还在使用完整数据集(仍然低于微调范式)的情感分类和自然语言推理任务中取得了令人惊讶的准确度。 查看搜索到的离散(但不再是自然语言)提示,您可以找到一些“触发标记”的解释,但其他许多只是特殊性。 目前还不清楚自动提示是否真的帮助LM回忆里面的“知识”,还是只是一种优化的替代方式,从预训练模型中的“彩票”中挑选“中奖彩票”。
软提示:我们真的需要提示中的离散词吗?
既然 AutoPrompt 已经对提示进行了基于梯度的搜索,为什么不从离散标记转向连续的“软提示”呢?例如,钟等人和 Qin&Eisner提出将“软提示”用于知识探测任务(LAMA 等),并且相对于离散提示取得了相当大的改进。这个想法非常简单——只需在输入序列中放入一些随机向量(与词汇表中的特定词嵌入无关)并调整它们,并修复预训练模型的其他部分。
除了探测任务之外,还有一些部署软提示的工作:Li 和 Liang将这个想法扩展到生成任务,并表明它在仅调整 0.1% 参数的情况下与微调性能相当。韩等人将软提示与手动模板相结合,在关系提取方面取得了卓越的性能。迄今为止,我所看到的关于软提示的最全面的研究来自 Lester 等人:他们在 T5 上应用了软提示,并表明只需调整提示(仅占总参数的一小部分),T5 就可以通过对整个模型进行微调来在 NLU 任务上获得同等性能。作者也喜欢这篇论文,因为它进行了广泛的消融研究,并展示了成功软提示的几个关键经验选择,包括词嵌入初始化、足够数量的软提示标记和对齐的预训练目标。除了参数效率,Lester 等人还证明软提示比完整模型微调具有更好的可转移性。
让我们回顾一下软提示的想法:它工作得非常好,并且在您不能(探测任务)或不会(模型太大或您想要所有任务的通用模型)接触模型参数时特别有效。微调软提示与基于提示的微调非常不同,后者允许优化整个模型,更重要的是,比标准微调更好地处理小样本情况。与其手动对应物不同,AutoPrompt 在少样本情况下效果不佳,据我所知,没有软提示论文认为它们实现了极好的少样本性能通过从离散的手动提示开始并微调整个模型来获得少量结果)。此外,正如莱斯特等人证明,在使用超过 100 亿个参数的预训练模型之前,软提示永远不会达到与 SuperGLUE 完全微调相同的性能!我认为值得研究如何进一步推动软提示以在少数情况下和较小的语言模型中更有效地工作。
上下文学习:一种新的元学习形式
我将 GPT-3 的成功归功于本文开头的两个模型设计:提示和演示(或上下文学习),但直到本节我才谈到上下文学习。 由于 GPT-3 的参数没有针对下游任务进行微调,因此它必须以另一种方式“学习”新任务——通过上下文。
GPT-3 简单地将训练集中的一些随机示例与实际查询(在本示例中为“cheese ⇒”)连接起来,并且由于预训练模型已经学会了从上下文中捕获模式和Transformers 的 self-attention 允许在这些实例中逐个进行比较,上下文学习的效果出奇地好。 GPT-3 论文称其为“元学习”,认为在阅读大量无监督文本后,语言模型可以“培养广泛的技能和模式识别能力”。作者假设在预训练期间“有时会在单个序列中嵌入重复的子任务”,类似于上下文学习的范式。后续工作进一步完善了使用演示的方式:Gao 等人;Liu等人说,不是随机抽样一些例子,而是采取类似于查询的上下文演示可以显着提高性能;Lu等人表明,即使演示的顺序也很重要并提出一种确定“最佳”顺序的方法。
虽然in-context learning只有在不能调优模型时才“需要”,当训练样例数量增加时很难泛化(因为模型的输入长度有限),研究如何更好地使用演示(即,如何进一步压缩 LM 学到的“元知识”)以及哪些预训练目标和数据可以提高上下文能力,可能会进一步帮助我们了解预训练 LM 的内部工作原理。
校准语言模型
提示很棒,但它也会带来来自预训练语料库的偏见。 例如,在零样本情感分类设置中,给定“N/A”作为输入,GPT-3 倾向于预测“正面”而不是“负面”,而预计将 50/50 的概率分配给两个对比标签。 另一个问题是同一对象的不同表面形式(例如,“计算机”和“PC”)可能会竞争概率质量,导致任务标签上的分布不理想。 赵等人给出的解决方案。和 Holtzman 等人 是校准:对有偏见的符号添加补偿,使它们被校准到无偏见的状态。
什么是真正的少样本设置?
关于少样本设置本身有很多讨论:众所周知,对小数据集的微调可能会受到不稳定性的影响,并且数据的不同分割可能会影响性能急剧下降。以前的工作采用了各种设置,但要考虑到小样本、多次采样小样本数据拆分和使用不同种子的多次试验的巨大差异,需要提供严格且忠实的小样本评估(这就是我们所做的)在我们的工作中)。另一个经常被忽视的问题是,不能在少数镜头的情况下假设一个大的开发集。为了解决这个问题,Schick 和 Schütze不采用开发集并采用固定的超参数(这类似于在这种波动的环境中“在黑暗中样本摄”,可能会产生不直观的结果),并且在我们的工作中,我们对与训练集大小相同的少量开发集进行采样,因此我们可以调整超参数,同时保持“少量”。
在最近的一篇论文中,佩雷斯等人认为,先前的工作通过或多或少地采用了许多用于超参数调整、模型开发或快速设计的保留示例,高估了 LM 的小样本性能,并且他们提倡“真正的小样本学习”设置.这与我们的观点一致,即您只能假设少量开发示例。然而,在现实世界中,很难实现“真正的小样本学习”,因为您需要足够数量的留存示例来验证您的模型至少在一两个任务上是有效的。只要设计可以很好地推广到其他的小样本任务(这些任务可以被称为“真正的小样本”),它就是一个很好的小样本模型。在我们的工作中,我们将 SST-2 和 SNLI 用于试点实验,并表明我们的方法可以很好地推广到其他 13 个 NLU 任务。
论文下载:https://arxiv.org/pdf/2012.15723.pdf
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢