
【论文标题】Multi-Task Self-Training for Learning General Representations
【作者团队】Golnaz Ghiasi, Barret Zoph, Ekin D. Cubuk, Quoc V. Le, Tsung-Yi Lin
【通讯作者】 Tsung-Yi Lin
【发表时间】2021/08/25
【机 构】Google Brain
【论文链接】https://arxiv.org/abs/2108.11353v1
【推荐理由】来自谷歌大脑的多任务自训练学习通用表征
对于计算机视觉来说,学习一个对许多任务都有效的单一通用模型仍然是一个挑战。本文介绍了多任务自训练(MuST),它利用独立的专业教师模型(例如,关于分类的ImageNet模型)中的知识来训练一个单一的通用学生模型。本文的方法有三个步骤。首先,在已标记的数据集上独立训练专业教师。然后,使用专业教师来标记未标记的数据集,以创建一个多任务的伪标记数据集。最后,这个数据集包含了在不同数据集/任务上训练的教师模型的伪标签,然后被用来训练一个多任务学习的学生模型。作者在6个视觉任务上评估学生模型的特征表示,包括图像识别(分类、检测、分割)和三维几何估计(深度和表面法线估计)。MuST在未标记或部分标记的数据集上是可扩展的,并且在大规模数据集训练时优于专门的监督模型和自监督模型。最后,作者表明MuST可以在已经用数十亿个例子训练的强大检查点的基础上进行改进。结果表明,自训练是一个很有前途的方向,可以聚合有标签和无标签的训练数据来学习一般的特征表示。
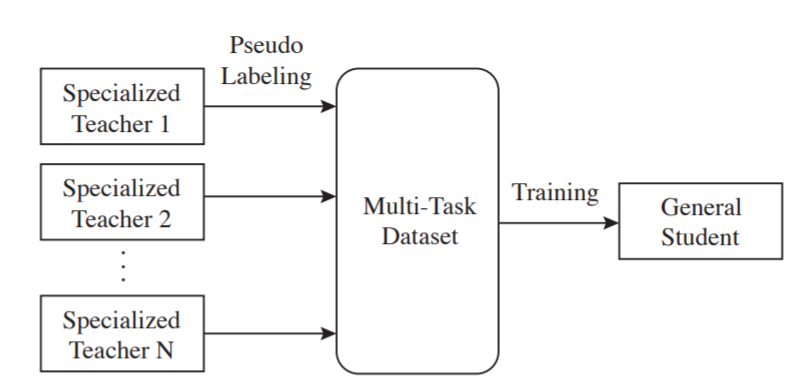
上图显示了MuST的框架。特定教师N代表在单一任务和数据集上训练的监督模型(例如,在ImageNet上训练的分类模型)。特定教师模型在他们自己的任务和数据集上独立训练,然后他们在一个共享的数据集上产生伪标签。最后,使用共享数据集上的伪(和监督)标签联合训练一个单一的普通学生模型。
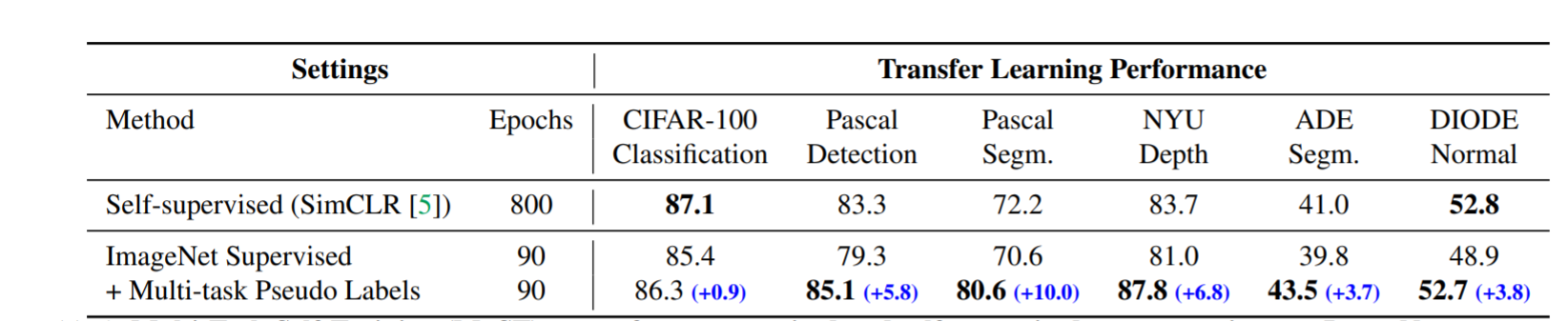
多任务自训练(MuST)在ImageNet上的表现优于有监督和自监督的表现。作者使用相同的预训练数据集(ImageNet)将MuST与最先进的自监督和监督学习进行比较。MuST学习了更多的通用特征,并在4/6个下游微调任务中取得了最佳性能。性能差异显示了不同训练目标的影响。
本文的贡献总结如下。
- 作者提出了多任务自我训练(MuST),这是一种简单的算法,通过多任务学习和伪标签来创建一般的视觉表征。
- 作者通过在几个数据集(如ImageNet、Objects365、COCO、JFT)上进行联合训练来学习一般的特征表征,其表现优于通过监督和自我监督方法学习的表征。
- 作者在6个计算机视觉任务上进行了实验,比较了监督、自监督和MuST,包括图像识别(分类、检测、分割)和三维几何估计(深度和表面法线估计)的任务。
- 与特定任务的最先进模型相比,MuST可以用来改进已经很强的检查点,并在各种任务上取得有竞争力的结果。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢